Большая языковая модель (Large Language Model, LLM)
Большая языковая модель (Large Language Model, LLM) — это тип искусственного интеллекта, который обучен работать с текстом: понимать, генерировать, пересказывать, дополнять, переводить и анализировать его.
Основная идея проста: модель обучается на огромных массивах текстов — книгах, статьях, диалогах, коде, документации и других источниках. На этом основании она учится предсказывать, какое слово или символ должно идти следующим в тексте, учитывая контекст.
Если разложить по ключевым признакам:
- «большая». Это значит, что у модели очень много параметров (весов) — часто миллиарды или даже сотни миллиардов. Чем больше параметров и чем больше данных для обучения, тем глубже модель «понимает» нюансы языка и сложные зависимости в тексте;
- «языковая». Модель работает с естественным языком (русский, английский и другими) и может понимать формализованные языки, например программирования. Она может разбирать грамматику, смысл и контекст, а также подстраивать стиль ответа;
- «модель». Это математическая структура, в которой хранится результат обучения — правила и связи, выведенные на основе обработанных данных.
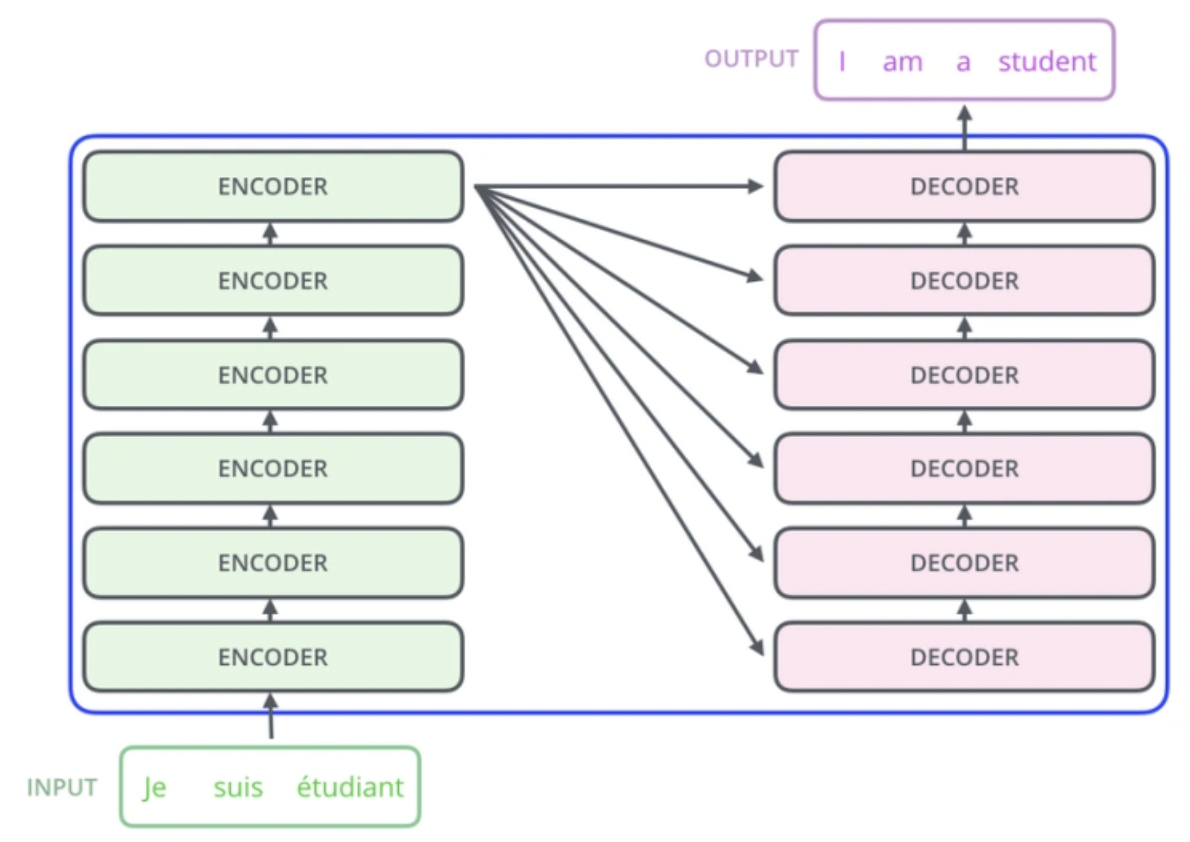
Для LLM используется архитектура нейросетей, чаще всего трансформеры (Transformer).
Принцип работы больших языковых моделей
Примеры известных больших языковых моделей
Принцип работы больших языковых моделей
Принцип работы LLM можно объяснить на трех уровнях: техническом, логическом и базовом.
1. Общая идея. LLM устроена так, чтобы предсказывать следующее слово (или токен) на основе предыдущего контекста. Например, если в тексте «Вода кипит при 100…» — модель с высокой вероятностью продолжит «градусах». Но, чтобы предсказания были осмысленными, она обучается на колоссальных объемах данных и использует сложную архитектуру нейросетей.
2. Основные этапы работы:
- сбор и подготовка данных. Миллиарды слов и фраз из книг, статей, сайтов, кодовых репозиториев. Данные очищаются от «мусора», приводятся к унифицированному формату. Текст разбивается на токены — минимальные фрагменты (слова, части слов, знаки препинания);
- архитектура — трансформер. В основе большинства LLM — архитектура Transformer (предложена в 2017 году). Главное новшество трансформеров — механизм внимания (attention): модель при обработке слова «смотрит» на весь контекст вокруг него и определяет, какие слова важны для смысла. Это позволяет учитывать дальние связи в тексте (например, помнить, о каком «он» шла речь пять предложений назад);
- обучение — предсказание следующего токена. Модель многократно «читаeт» текст и учится подбирать правильное следующее слово. Внутри происходит настройка параметров (весов) нейросети, чтобы уменьшить разницу между прогнозом и реальным словом;
- генерация ответа. Когда вы задаете вопрос, модель превращает его в токены, пропускает через слои нейросети, для каждого шага вычисляет вероятности для всех возможных токенов, выбирает следующий токен и повторяет процесс, пока не получит полный ответ.
3. Технически процесс выглядит следующим образом:
- вход → токенизация → числовые векторы (эмбеддинги);
- слои трансформера: Self-Attention (анализ контекста), Feed Forward Network (обработка информации), Layer Normalization (стабилизация вычислений);
- выход → вероятность каждого токена → выбор с учетом настроек (температура, top-k, top-p).
Модель хранит не целые тексты или базы знаний в привычном виде, а статистические связи между словами и понятиями. Она не «знает» фактов напрямую, а воспроизводит закономерности, которые видела на обучении. «Понимание» в LLM — это математическая обработка контекста, а не осмысленное мышление.
Где применяются LLM
Большие языковые модели применяются во множестве сфер: от автоматизации бизнеса до научных исследований. Рассмотрим основные направления.
1. Бизнес и корпоративные задачи:
- чат-боты и виртуальные ассистенты. Автоматическое общение с клиентами, ответы на типовые вопросы, обработка заявок. К примеру, чат-поддержка банка или маркетплейса;
- автоматизация документооборота. Составление, проверка и редактирование контрактов, коммерческих предложений, писем;
- аналитика данных. Извлечение ключевой информации из отчетов, логов, отзывов;
- маркетинг и реклама. Генерация текстов для лендингов, постов, email-рассылок, подбор заголовков с учетом SEO.
2. Образование, самообучение и продуктивность:
- объяснение сложных тем простыми словами. Преподаватели и студенты используют LLM для упрощения учебного материала;
- подготовка учебных материалов. Конспекты, шпаргалки, планы обучения;
- создание персонализированных учебных планов. Генерация тестов, практических заданий, подбор дополнительных материалов;
- обучение языкам. Диалоги, тренировка грамматики и словарного запаса, перевод материалов на разные языки;
- личная продуктивность. Составление списков дел, планов проектов, расписаний. Формулировка писем, заявлений, постов. Подготовка к выступлениям и презентациям.
3. Разработка ПО и ИТ:
- генерация и отладка кода. Автодополнение, объяснение ошибок, конвертация кода между языками, например GitHub Copilot;
- документация и комментарии. Автоматическое создание и обновление технической документации;
- тестирование ПО. Генерация тест-кейсов и автоматических сценариев проверки.
4. Медицина:
- обработка медицинской документации. Автоматическое извлечение ключевой информации из историй болезни;
- поддержка принятия решений. Системы, помогающие врачам анализировать симптомы и исследования;
- обучение медицинскому персоналу. Симуляция диалогов «врач–пациент» для тренировки.
5. Наука и аналитика:
- анализ больших массивов текстов. Научные статьи, отчеты, судебные решения;
- автоматическое суммирование. Выделение ключевых выводов из длинных документов;
- поиск гипотез и идей. Генерация исследовательских направлений на основе существующих данных.
6. Креатив и медиа:
- создание сценариев, статей, стихов. Генерация художественных текстов, новостей, рекламных слоганов, идей для контента;
- работа с видео и аудио. Создание субтитров, расшифровка интервью, генерация описаний;
- игры. Генерация диалогов для персонажей, сюжета, миров.
Примеры известных больших языковых моделей
Отметим наиболее популярные сегодня опенсорсные языковые модели.
- GPT-J. Разработка команды EleutherAI. Эта модель мощнее и эффективнее своего предшественника GPT-Neo, обладает 6 миллиардами параметров и демонстрирует высокую производительность в задачах обработки естественного языка. Обучение на расширенном наборе данных позволило GPT-J генерировать тексты высокого качества.
- BERT. Модель от Google, ставшая основой для целого поколения последующих решений в NLP. Широко применяется для анализа и классификации текстов.
- T5. Модель Google, представленная в 2020 году. Применяет единый подход ко всем задачам NLP, будь то перевод, суммирование, классификация или генерация текста. Любая задача формулируется как преобразование одного текста в другой, что делает обучение универсальным и удобным.
- Mistral. Современная языковая модель компании Mistral AI. Отличается качественной обработкой текста и доступна в разных конфигурациях, включая крупные варианты с большим числом параметров. Обучена на разнообразных источниках, благодаря чему выдает разносторонние и точные ответы.
- Yandex YaLM. Модель Яндекса, представленная в 2023 году. Обучена как на русскоязычных, так и на англоязычных данных, что повышает качество генерации текста. Выпускается в нескольких версиях, различающихся по размеру и числу параметров.
Как выбрать LLM
Выбор подходящей большой языковой модели зависит от того, какие задачи вы хотите решать и какими ресурсами располагаете. Разберем ключевые шаги.
- Определите назначение. Четко сформулируйте, для чего вам нужна LLM: генерация текста, ответы на вопросы, перевод, анализ данных или что-то другое. Так, GPT-Neo и GPT-J хорошо справляются с генерацией текста и обработкой естественного языка, подходят для чат-ботов и создания контента, а BERT эффективна в классификации, извлечении информации и системах вопросов-ответов.
- Изучите документацию. Наличие подробных инструкций по установке и использованию поможет быстрее начать работу и избежать ошибок при интеграции.
- Проверьте требования к ресурсам. Многие модели требуют значительных вычислительных мощностей. Убедитесь, что у вас есть подходящее оборудование или доступ к облачным сервисам.
- Оцените активность сообщества. Активные форумы и группы поддержки значительно упрощают решение проблем и обмен опытом.
- Изучите лицензию. Проверьте, разрешено ли использование модели в вашем сценарии — особенно если проект коммерческий. Некоторые лицензии ограничивают модификацию или монетизацию.
- Проведите тестирование. Перед внедрением попробуйте модель на небольших задачах. Это поможет понять, подходит ли она по качеству и скорости для вашего проекта.
Будущее LLM
Будущее больших языковых моделей сейчас формируется на стыке технологий, этики и экономики, и уже можно выделить несколько четких направлений развития.
1. Рост мультимодальности. Сегодня LLM в основном работают с текстом, но все активнее интегрируются с другими типами данных: изображениями, видео, аудио, 3D-моделями, сенсорными потоками. Например, GPT-5, Gemini, Claude 3 могут анализировать картинку, понять ее контекст и ответить голосом. Будущее — единые модели, способные воспринимать и генерировать контент во всех форматах.
2. Персонализация и адаптация. LLM будут «подстраиваться» под конкретного пользователя, учитывая стиль общения, предпочтения и цели. Появятся персональные ИИ-агенты, которые смогут вести переписку, планировать дела, управлять финансами и работать в фоновом режиме. Важный тренд — локальное хранение данных и приватное обучение, чтобы ИИ знал вас, но не «сливал» информацию в облако.
3. Интеграция в рабочие процессы. LLM перестанут быть «отдельным чатом» и будут встроены прямо в:
- офисные пакеты (Word, Excel, Google Docs);
- CRM- и ERP-системы;
- IDE для программистов;
- корпоративные мессенджеры.
Они станут «невидимыми помощниками», которые работают внутри привычных инструментов.
4. Повышение надежности и правдоподобности:
- борьба с «галлюцинациями» (выдуманными фактами);
- интеграция с внешними базами данных и поисковыми системами для актуализации ответов;
- переход от «вероятностного угадывания» к гибридным системам, где LLM + логический модуль совместно формируют ответ.
5. Снижение барьеров входа. Модели становятся дешевле, меньше и быстрее, работают на смартфоне офлайн. Это позволяет компаниям разворачивать собственные ИИ без передачи данных сторонним сервисам.
6. Регулирование и этика:
- усиление законов об авторском праве, конфиденциальности и ответственности за контент, созданный ИИ;
- введение маркировки AI-контента;
- развитие технологий проверки подлинности информации.
7. Эволюция к автономным ИИ-агентам. LLM станут основой для систем, которые могут:
- ставить себе цели;
- планировать шаги для их достижения;
- выполнять задачи в интернете (заказывать, бронировать, анализировать).
Появятся цепочки агентов — распределенные ИИ, которые совместно решают сложные задачи.
Вопросы-ответы
- Предобучение. На больших наборах данных модель учат предсказывать следующее слово.
- Дотюнинг. Подгонка под конкретные задачи, например ответы на вопросы в диалоговом формате.
- Инструкционное обучение. Модель учат выполнять команды в понятном человеку виде («Напиши…», «Объясни…», «Что делать, если…»).
Отсутствие «понимания» и реального мышления, ограниченная актуальность знаний, возможность ошибок и выдумок (галлюцинаций), зависимость от качества данных, ограничения в логических рассуждениях, этические и правовые ограничения.
Четко формулируйте запрос, давайте контекст, используйте итеративный подход, проверяйте факты, комбинируйте с другими инструментами.



