Data Lake (озеро данных)
Data Lake (озеро данных) — это централизованное хранилище, в котором собираются, хранятся и обрабатываются огромные объемы структурированных, полуструктурированных и неструктурированных данных. В отличие от традиционных баз данных и классических хранилищ (Data Warehouse), озеро данных не требует предварительной структуризации информации. Она помещается в него в «сыром» виде — такой, какой поступает из источников: журналов событий, логов приложений, данных IoT-устройств, транзакций, изображений, видео, аудио, отчетов и других.
Главная идея Data Lake — гибкость и масштабируемость. Оно позволяет организациям хранить все подряд без необходимости заранее проектировать сложные схемы данных. Пользователи могут позднее обрабатывать и структурировать нужные фрагменты информации для конкретных задач — аналитики, машинного обучения, отчетности и прогнозирования.
Озеро данных служит своего рода «резервуаром» для цифрового контента компании. Это место, где соединяются источники данных — внутренние и внешние — и формируется фундамент для Data Science, Big Data-аналитики и искусственного интеллекта.
Кому и для чего нужны озера данных
В чем разница между озерами и хранилищами данных
Масштабируемость и производительность
Поддержка продвинутой аналитики и AI
Интеграция с BI и ETL-инструментами
Реальное время и потоковые данные
Долговременное и надежное хранение
Упрощенная интеграция и совместная работа
Поддержка Data Governance и метаданных
Кому и для чего нужны озера данных
Data Lake нужен прежде всего тем организациям, которые работают с большими объемами разнородных данных. Это могут быть корпорации, госструктуры, стартапы, исследовательские институты и технологические компании.
- Крупные компании и корпорации. Финансовые организации, телеком-операторы, розничные сети, производственные предприятия ежедневно генерируют терабайты информации. Им необходимо хранить все данные для аудита, отчетности, улучшения бизнес-процессов и прогнозирования спроса. Data Lake позволяет централизовать хранение информации и получать аналитические инсайты без потери контекста.
- Команды аналитики и Data Science. Аналитики и дата-ученые нуждаются в доступе к исходным, неочищенным данным, чтобы строить модели машинного обучения и исследовать зависимости. Озеро данных дает такую возможность, устраняя барьеры между источниками и инструментами обработки.
- Разработчики и архитекторы данных. Data Lake позволяет упростить интеграцию различных систем, обеспечивая гибкий подход к данным и возможность построения современных архитектур, например Data Lakehouse, объединяющих принципы озера и хранилища.
- Государственные структуры и исследовательские организации. Для научных и государственных проектов важно собирать большие объемы данных из разнородных источников: спутниковых снимков, сенсоров, социальных сетей, открытых баз. Data Lake становится удобной платформой для этого, обеспечивая долговременное хранение и масштабируемость.
Как устроено озеро данных
В основе архитектуры Data Lake лежит принцип «store now, analyze later» — «сохрани сейчас, проанализируй потом». Это означает, что данные не проходят этап трансформации перед загрузкой (в отличие от ETL-подхода в Data Warehouse). Вместо этого применяется метод ELT (Extract, Load, Transform): сначала данные извлекаются из источников, затем загружаются в озеро, а только потом — по мере необходимости — трансформируются.
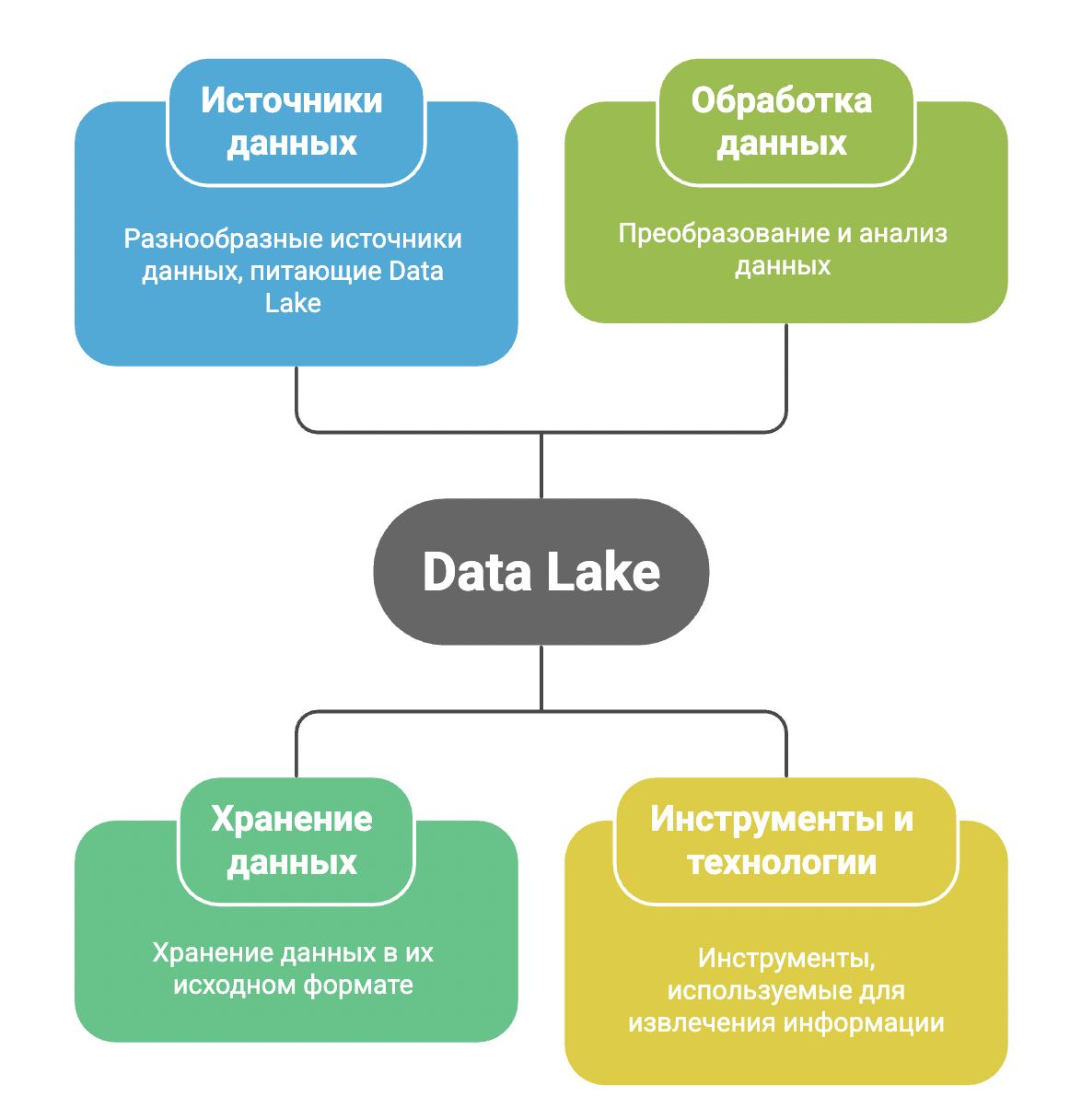
Рассмотрим основные компоненты архитектуры.
- Источники данных. Это могут быть базы данных, CRM-системы, сенсоры, API, мобильные приложения, веб-сервисы, ERP-системы, потоки логов и файлы.
- Зона приема (Landing Zone). На этом уровне данные поступают в сыром виде. Они могут храниться в неструктурированных форматах — JSON, CSV, Parquet, Avro, XML, изображения, видео и других.
- Зона обработки (Processing Zone). Здесь данные очищаются, каталогизируются, иногда агрегируются.
- Зона хранения (Storage Zone). Долговременное хранилище, оптимизированное для объемов и производительности. Часто применяются облачные сервисы.
- Зона потребления (Consumption Zone). Обработанные данные используются аналитическими инструментами, BI-платформами, скриптами Python, SQL-запросами, моделями машинного обучения.
Как работают Data Lake
Работа озера данных строится вокруг нескольких процессов.
- Интеграция данных. Информация поступает из различных источников с помощью коннекторов и стриминговых систем.
- Каталогизация. Чтобы данные не превратились в хаос, применяется Data Catalog — метаданные, описывающие источники, форматы, схемы и контекст. Без каталога озеро данных может превратиться в «болото данных» (Data Swamp).
- Управление доступом и безопасностью. Используются механизмы разграничения прав, шифрования, аутентификации и мониторинга активности, чтобы защитить данные.
- Аналитика и машинное обучение. Data Lake предоставляет возможность подключать инструменты анализа (Power BI, Tableau, Apache Superset) и ML-платформы (TensorFlow, PyTorch, Databricks ML).
- Масштабирование. Благодаря облачным технологиям Data Lake может расти без ограничения, обеспечивая хранение петабайт информации и миллионы запросов.
В чем разница между озерами и хранилищами данных
Data Lake и Data Warehouse (хранилище данных) — это два разных подхода. Вот основные отличия:
| Характеристика | Data Lake | Data Warehouse |
|---|---|---|
| Тип данных | Сырые, неструктурированные, полуструктурированные | Структурированные |
| Подход | ELT | ETL (Extract, Transform, Load) |
| Гибкость | Высокая | Низкая |
| Пользователи | Аналитики, инженеры, Data Scientists | Бизнес-аналитики |
| Цель | Исследование и машинное обучение | Отчетность и BI |
| Стоимость хранения | Низкая | Выше |
| Пример технологий | Hadoop, S3, Databricks | Snowflake, BigQuery, Redshift |
На практике многие компании объединяют оба подхода, создавая Data Lakehouse — гибридную систему, сочетающую преимущества озера данных (масштаб и гибкость) с надежностью и структурой хранилища.
Плюсы озер данных
Несмотря на сложность архитектуры, Data Lake обладают рядом преимуществ, которые делают их основой современной экосистемы работы с данными. Ниже приведены главные выгоды, которые объясняют популярность этого подхода в корпоративной и научной среде.
Гибкость и универсальность
Data Lake способен хранить любые типы данных — структурированные (таблицы, базы данных), полуструктурированные (JSON, XML, CSV) и неструктурированные (аудио, видео, изображения, тексты). Это делает систему универсальной и независимой от конкретных форматов или источников.
Компании могут собирать данные из CRM, ERP, IoT, логов, соцсетей и внешних API в одном месте, не заботясь о согласовании схем или структурах на этапе загрузки. Это значительно ускоряет процессы интеграции.
Масштабируемость и производительность
Современные Data Lake-решения, особенно облачные, обеспечивают почти неограниченное масштабирование. Объем данных может расти от гигабайт до петабайт без существенного роста затрат.
Благодаря распределенной архитектуре озера данных поддерживают параллельную обработку и потоковую загрузку, что позволяет одновременно работать с множеством процессов — от очистки до аналитики и машинного обучения.
Снижение стоимости хранения
В отличие от традиционных Data Warehouse, где данные требуют строгой структуры и оптимизации под запросы, озера хранят данные «как есть». Это означает, что можно использовать дешевое объектное хранилище без необходимости постоянного пересоздания схем или индексов.
Кроме того, компании экономят на предварительной обработке (ETL): данные поступают сразу, а структурирование выполняется по мере необходимости (ELT).
Поддержка продвинутой аналитики и AI
Data Lake — идеальная среда для машинного обучения, Data Science и искусственного интеллекта.
Благодаря доступу к полным, необработанным наборам данных, аналитики могут строить точные модели прогнозирования, проводить глубокие исследования, использовать нейросети и анализировать паттерны поведения клиентов.
Также озера данных легко интегрируются с популярными ML-фреймворками: TensorFlow, PyTorch, Apache Spark MLlib и Databricks.
Интеграция с BI и ETL-инструментами
Озера данных совместимы с большинством аналитических платформ: Power BI, Tableau, Qlik, Apache Superset. Это позволяет объединить «сырые» данные из Data Lake с обработанными наборами из хранилища, обеспечивая сквозную аналитику — от оперативных отчетов до предиктивных моделей.
Реальное время и потоковые данные
Современные Data Lake поддерживают стриминговую обработку, что делает возможным анализ данных в реальном времени, например событий от IoT-устройств, веб-кликов или транзакций.
Такие системы, как Apache Kafka, Flink или Kinesis, позволяют мгновенно собирать и обрабатывать информацию, обеспечивая оперативные инсайты и реакцию на события.
Долговременное и надежное хранение
Data Lake — это долговременный архив цифровых активов компании.
Данные сохраняются в первозданном виде, что обеспечивает возможность повторного анализа, аудита и переобучения моделей машинного обучения в будущем.
Многие решения автоматически создают резервные копии и версионность, что защищает от потери информации.
Упрощенная интеграция и совместная работа
Data Lake объединяет данные из разных подразделений и делает их доступными для всех заинтересованных сторон — аналитиков, инженеров, маркетологов, разработчиков.
Благодаря этому компании строят единую экосистему данных, устраняя изолированные хранилища и улучшая взаимодействие команд.
Поддержка Data Governance и метаданных
Современные Data Lake-платформы включают инструменты управления метаданными, каталогизацию (Data Catalogs) и политики доступа. Это обеспечивает прозрачность, безопасность и контроль качества данных, что особенно важно для крупных организаций и регулируемых отраслей.

Другие термины

Эта статья и другие полезные ресурсы click.ru — после бесплатной регистрации
Вы получите доступ к функционалу экосистемы:
- Все рекламные площадки в одном окне
- Мастер маркировки любой рекламы
- Профессиональные инструменты для решения рутинных задач (дашборды, защита от скликивания и многое другое)
- Возврат до 19% на рекламу
- Бесплатный доступ в платные маркетинговые сервисы


