Краулинг для контекста: 5 кейсов в помощь PPC-специалистам

Как с помощью автоматизации процессов упростить работу с контекстной рекламой: кейсы по краулингу и парсингу данных.
Из статьи вы узнаете:
- кейс 1: получение списка всех URL сайта для определения посадочных страниц с помощью краулинга.
- кейс 2: парсинг содержимого метатегов страниц для быстрой генерации рекламных кампаний.
- кейс 3: проверка кодов ответа сервера и времени загрузки посадочных страниц рекламных объявлений и дополнительных ссылок.
- кейс 4: мониторинг цен конкурентов для корректировки ставок.
- кейс 5: сбор данных для создания фида динамического ремаркетинга.
Вне зависимости от сферы и области знаний каждый стремится автоматизировать рабочие процессы. Для PPC-специалистов Юля Телижняк, контент-маркетолог Netpeak Spider, собрала примеры нескольких рутинных задач, выполнение которых можно упростить с помощью краулинга и парсинга данных.
Кейс 1: получение списка всех URL сайта для определения посадочных страниц с помощью краулинга
Когда вы работаете с крупным интернет-магазином, собрать вручную весь список страниц с товарами — достаточно сложная задача. И на ее выполнение может уйти не один день.
Чтобы облегчить себе работу и не ходить по сайту, собирая нужные страницы руками, вы можете выгрузить весь список URL в кратчайшие сроки с помощью краулера. Как это сделать:
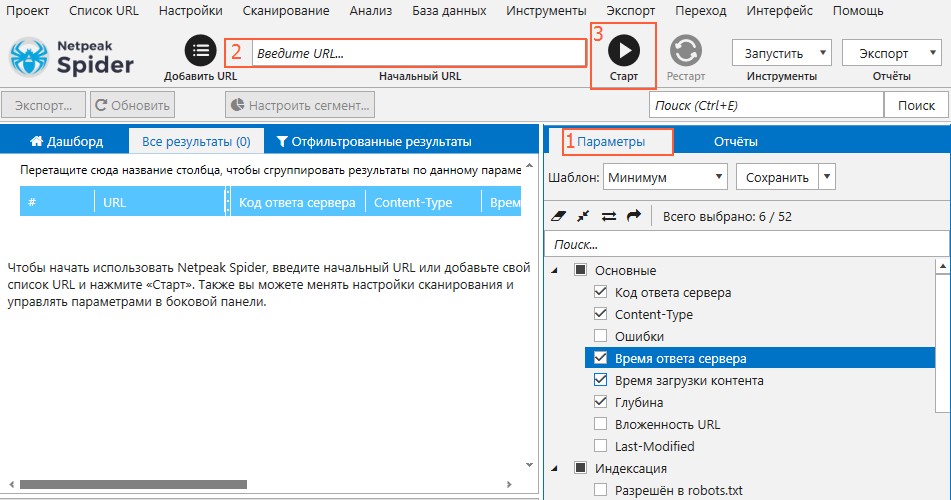
- Откройте Netpeak Spider.
- На вкладке «Параметры» на боковой панели выберите шаблон «Минимум»: это значительно ускорит краулинг, если ваша основная цель — добыть список страниц.
- Введите домен сайта и запустите сканирование с помощью кнопки «Старт». Дождитесь окончания сканирования для сбора нужных данных.
Итак, вы получили список всех URL сайта. Далее можно приступать к их анализу для определения потенциальных лендингов для контекстной рекламы.
Кейс 2: парсинг содержимого метатегов страниц для быстрой генерации рекламных кампаний
Чтобы ускорить создание рекламных кампаний, в качестве заголовков и описаний можно использовать содержимое метатегов самих страниц. Чтобы собрать их со всего сайта за один раз с помощью Netpeak Spider, проделайте следующие шаги:
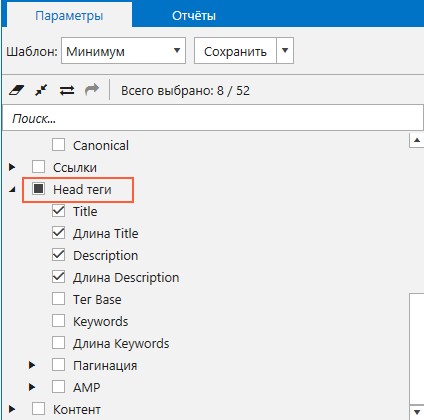
- Перед сканированием на вкладке «Параметры» отметьте пункты «Title» и «Description» из раздела «Head теги». Соответствующие каждой странице метаданные будут представлены в общей таблице с результатами.
- Запустите сканирование и дождитесь завершения процедуры.
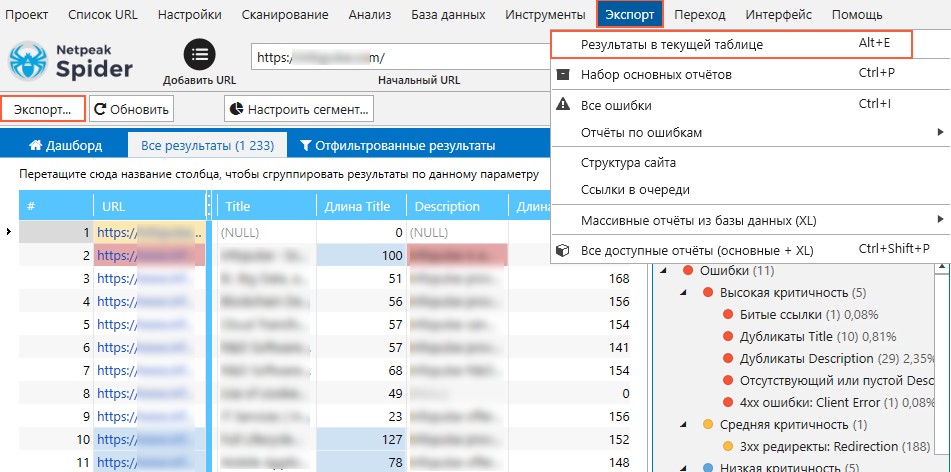
- Выгрузите результаты с помощью кнопки «Экспорт» в правом верхнем углу программы, либо воспользуйтесь одноименным меню.
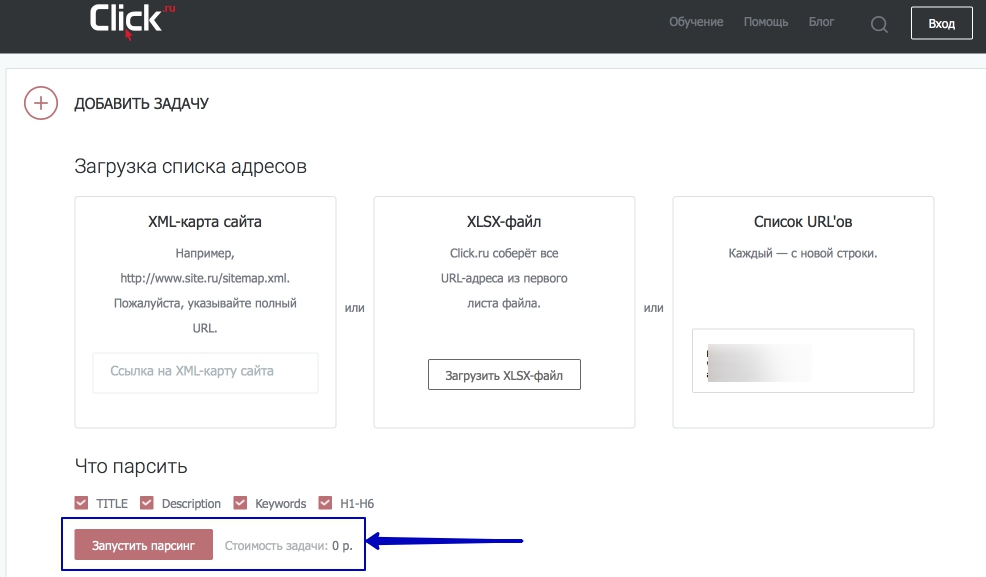
Парсинг метаданных также удобно проводить с помощью инструмента от Click.ru. Делается это следующим образом:
- В сервисе выберите удобный способ загрузки списка адресов.
- Отметьте необходимые данные.
- Запустите парсинг.
- По окончании выгрузите результаты в таблицу формата .csv одним кликом.
Имея итоговые данные, можно приступать к составлению объявлений. Кстати, вы можете использовать специальный шаблон, по которому это делать удобнее.
Кейс 3: проверка кодов ответа сервера и времени загрузки посадочных страниц рекламных объявлений и дополнительных ссылок
На этапе тестирования посадочных страниц важно проследить, чтобы для каждой из них сервер отдавал правильные коды ответа сервера (200 OK), а скорость загрузки не превышала допустимые пределы (не более 500 ms). Иначе показатели отказов будут умеренно расти.
Проверим эти два параметра:
- На боковой панели отмечаем параметры «Код ответа сервера», «Время ответа сервера» и «Время загрузки контента».
- Загружаем список посадочных страниц, выбрав «Список URL» в качестве способа загрузки. Запускаем сканирование.

- Просматриваем результаты сканирования на вкладке «Все результаты», а на боковой панели проверяем, не было ли обнаружено ошибок, связанных с проверяемыми параметрами.
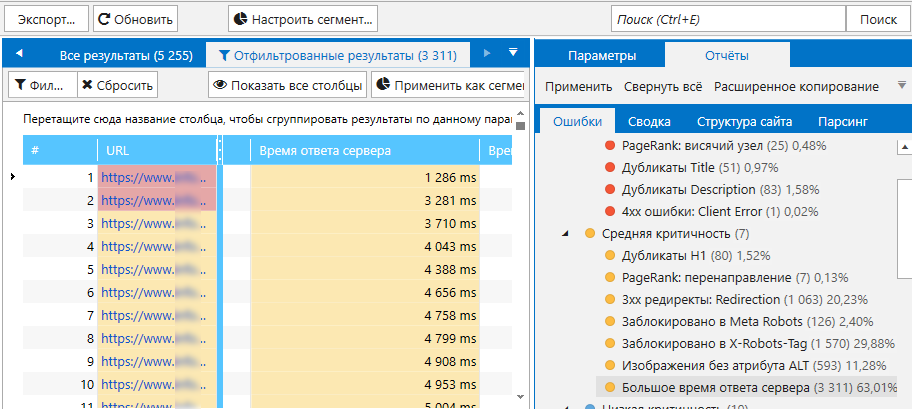
В Google Ads есть скрипт проверки кодов ответа сервера URL объявлений и расширений в рекламных кампаниях. Однако скрипт позволяет за один раз проверить до 20 000 URL. Поэтому в случае работы с большими сайтами (от 100 000 страниц) краулер сразу просканирует все URL без необходимости повторения итераций.
К слову, проверять URL важно не только на этапе предварительного тестирования товарных страниц, но и регулярно после запуска рекламных кампаний.
Кейс 4: мониторинг цен конкурентов для корректирования ставок
Разница в цене товара на вашем сайте и сайтах конкурентов может служить причиной для корректировки ставок. Например, было бы вполне оправданно повысить ставку для лендинга товара, у которого цена более выигрышная по сравнению с конкурентами.
Но согласитесь, мониторить цены — процедура трудозатратная. Чтобы ее ускорить и автоматизировать, воспользуйтесь парсером, который соберет все нужные данные за вас. Для этого необходимо:
- Перейти на карточку товара.
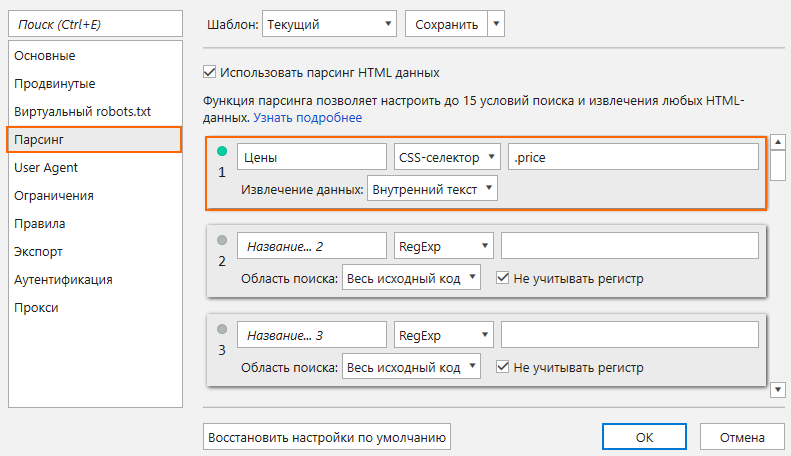
- Выделив цену, перейти в «Просмотр кода» и скопировать CSS-селектор элемента.
- В Netpeak Spider перейти к настройкам парсинга, вставить скопированный элемент в соответствующее поле и выбрать тип поиска «CSS-селектор». Сохранить настройки.
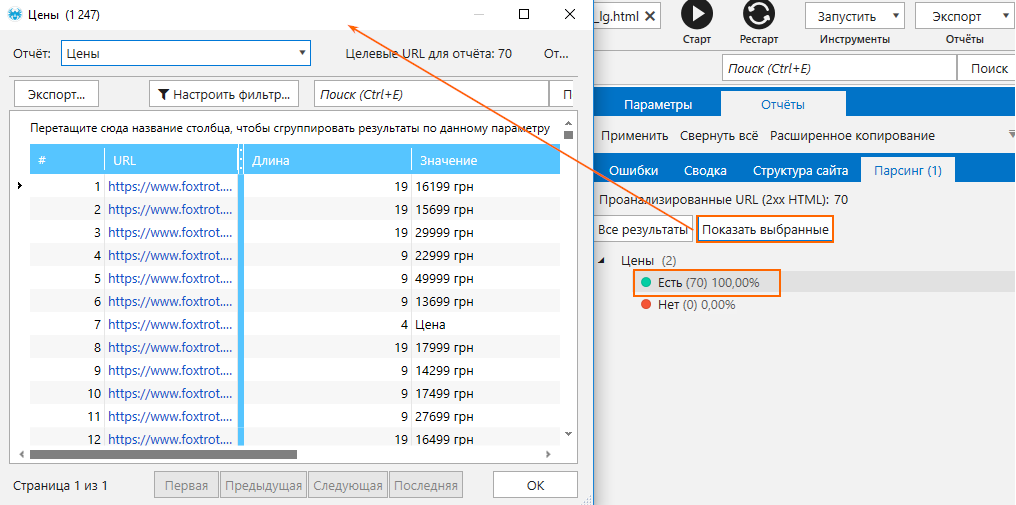
- В адресную строку поместить сайт, с которого вы хотите «вытянуть» цены.
- Запустить сканирование.
По итогу вы сможете ознакомиться с данными на вкладке «Парсинг» на боковой панели.
Таким же образом можно спарсить цены основных конкурентов для сравнительного анализа с текущими ценами на сайте. Для этого нужно выбрать несколько основных конкурентов, вручную подготовить перечень товаров, после чего «вытянуть» цены. После сравнительного анализа сделать выводы и решить, стоить ли пересматривать ценовую политику. Сохранив список товаров, вы можете периодически сканировать эти URL, чтобы актуализировать данные по ценам.
Кейс 5: сбор данных для создания фида динамического ремаркетинга
Кейс применяется при условии, если на сайте настроен тег ремаркетинга Ads, из которого можно вытянуть данные для каталога товаров. По тому же принципу, что и для парсинга цен, можно собирать элементы для создания фида динамического ремаркетинга:
- ID (идентификатор);
- Item Title (название);
- Item Description (описание);
- Final URL (ссылка);
- Image URL (ссылка на изображение);
- Price.
О сборе Title и Description речь шла во втором кейсе, и для генерации фида этот способ тоже подходит.
Поиск id и image_link можно осуществить путем парсинга по тому же принципу, как мы собирали цены. Для этого на странице товара необходимо открыть «Просмотр кода» и найти необходимые элементы. В случае поиска идентификатора мы ищем динамические параметры для тега ремаркетинга и копируем XPath тега script.
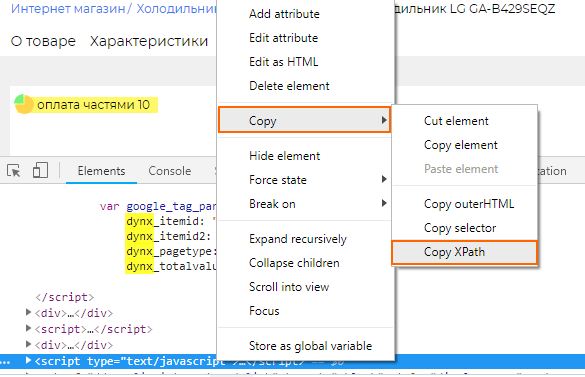
Затем вставляем полученный XPath в соответствующее поле в настройках парсинга Netpeak Spider, выбрав тип извлечения данных «Внутренний HTML-код».
Для парсинга image_link также копируем XPath.
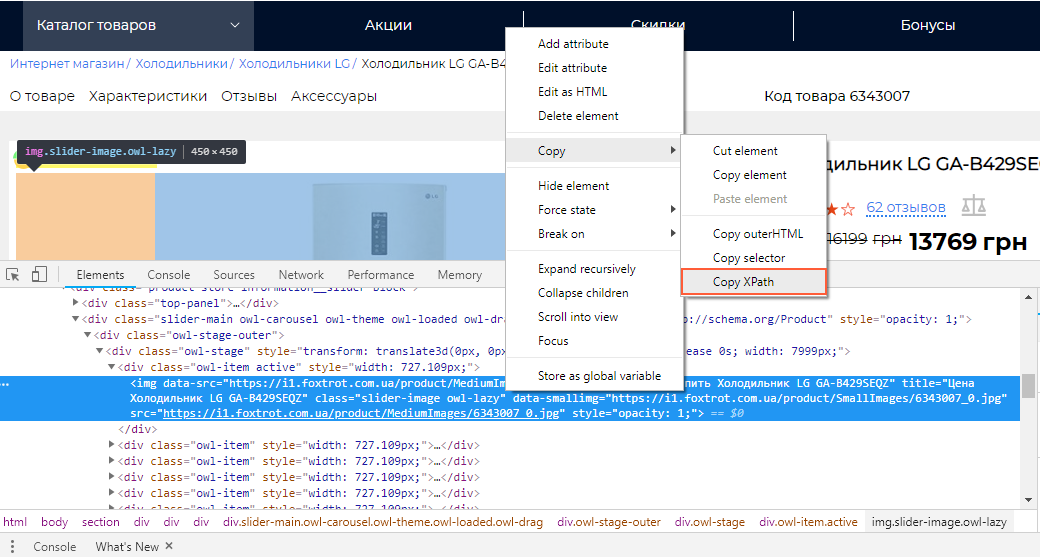
В настройках задаём «Извлечение данных» → «Значение атрибута». Название атрибута — «src» (содержит ссылку на наше изображение). После того как программа извлечет данные, их можно перенести в таблицу и приступить к созданию фида.

Когда код тег ремаркетинга не установлен на сайте, то собирать данные нужно следующим образом:
- Спарсить цены по аналогии с описанным алгоритмом, но вместо ID взять артикул в карточке товара.
- Настроить тег ремаркетинга Ads с помощью Google Tag Manager. Чтобы ID элемент в фиде совпадал с dynx_itemid на страницах карточек, добавить артикул/код в dynx_itemid.
Подводим итоги
Процесс сбора информации при помощи краулинга и парсинга данных значительно упрощает работу PPC-специалиста, особенно когда рекламные кампании запускаются с нуля.
С помощью краулера вы можете:
- получить список всех URL сайта для определения посадочных страниц;
- извлечь содержимое метатегов со страниц для быстрой генерации рекламных объявлений;
- проверить коды ответа сервера и время загрузки посадочных страниц в рекламных объявлениях и дополнительных ссылках;
- проанализировать цены конкурентов;
- собрать данные для создания товарных фидов.





