Как быстро уточнить частотность запросов в Wordstat


В современной аналитике поисковых запросов, собранных через Wordstat, важна оперативность уточнения их частотности. Если ниша широкая, ручная проверка может занять не один день. Использование операторов соответствия и применение дополнительных фильтров ускоряет процесс. Но и это не панацея для ниш, включающих сотни и тысячи вариантов. В статье рассмотрим стандартные способы отбора, а также автоматические, такие как инструмент «Парсер Wordstat» от click.ru, который за пару минут собирает частотность тысяч ключевых слов в указанных регионах.
Оглавление
Зачем нужна частотность запросов в Wordstat
Частотность запросов в Wordstat нужна в первую очередь для оценки спроса, чтобы понять, сколько людей ищут тот или иной товар (услугу). Это помогает понять объем потенциальной аудитории. Но есть и другие причины, по которым важна проверка частоты.
- Приоритизация ключевых фраз: помогает выбрать наиболее релевантные и перспективные словосочетания для контент-стратегии и рекламных кампаний.
- Формирование семантического ядра: объединяет похожие ключи, позволяет расширить семантику и выявить новые ниши.
- Прогноз трафика и бюджетов: можно приблизительно оценить ожидаемый трафик и рассчитать бюджет на SEO и контекстную рекламу.
- Оценка конкуренции и рисков: высокочастотные варианты часто требуют больше ресурсов, поэтому можно заранее учесть сложности ранжирования и ставки.
Ручной сбор частотностей в Wordstat
Проверить частотность запросов можно ручным методом. Вы по очереди набираете фразы в поиск и разбираете цифры. Это может занять время при большом объеме данных, но дает точные результаты для семантического ядра, поисковой оптимизации и настройки рекламы.
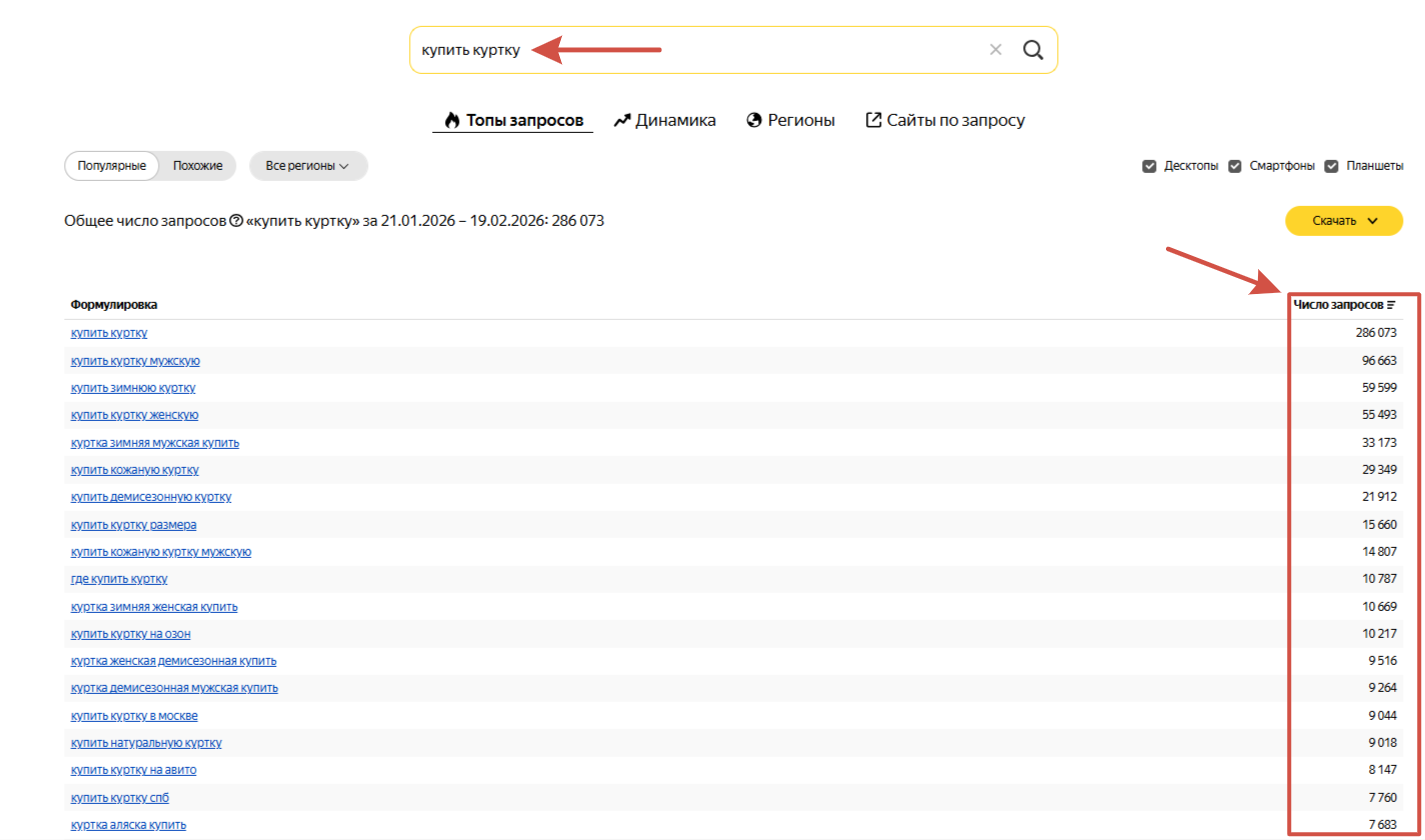
Если вы выбираете этот способ, лучше скачивать списки запросов в Excel и работать с этой таблицей. Позже можно будет применить их массовую загрузку в рекламную кампанию.
Операторы соответствия для точной статистики
По принципу фильтрации это та же самая ручная проверка, но более достоверная. Для уточнения используем операторы соответствия.
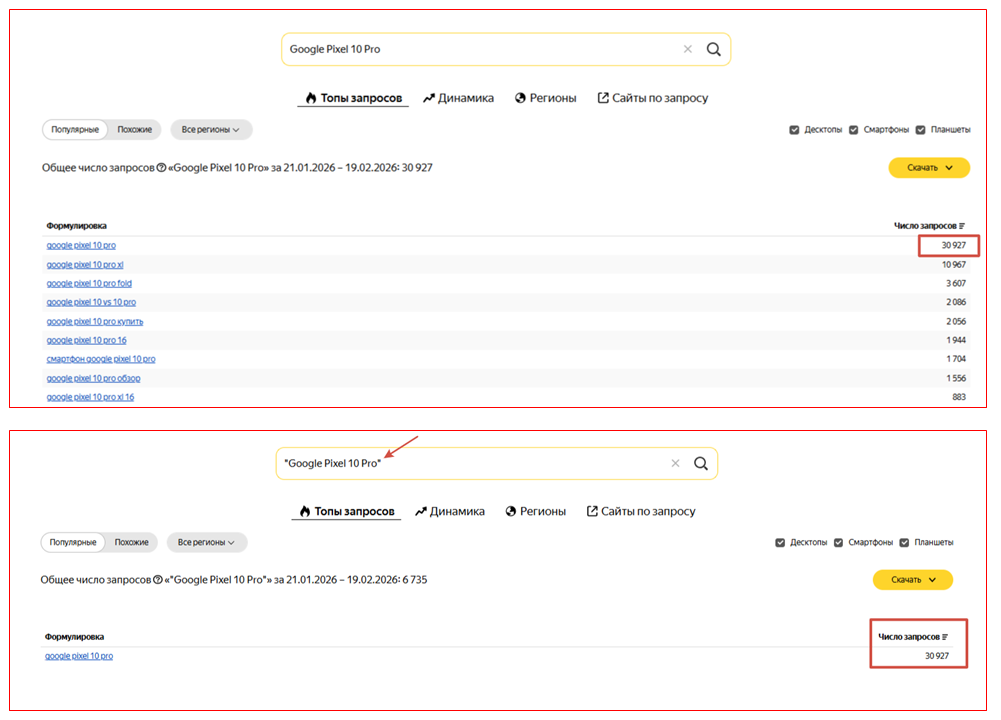
1. Кавычки. Оператор позволяет проверить частоту использования именно этой фразы, без вариантов с другими словами внутри нее. В целом, ту же самую цифру мы видим на первом месте списка и без кавычек.
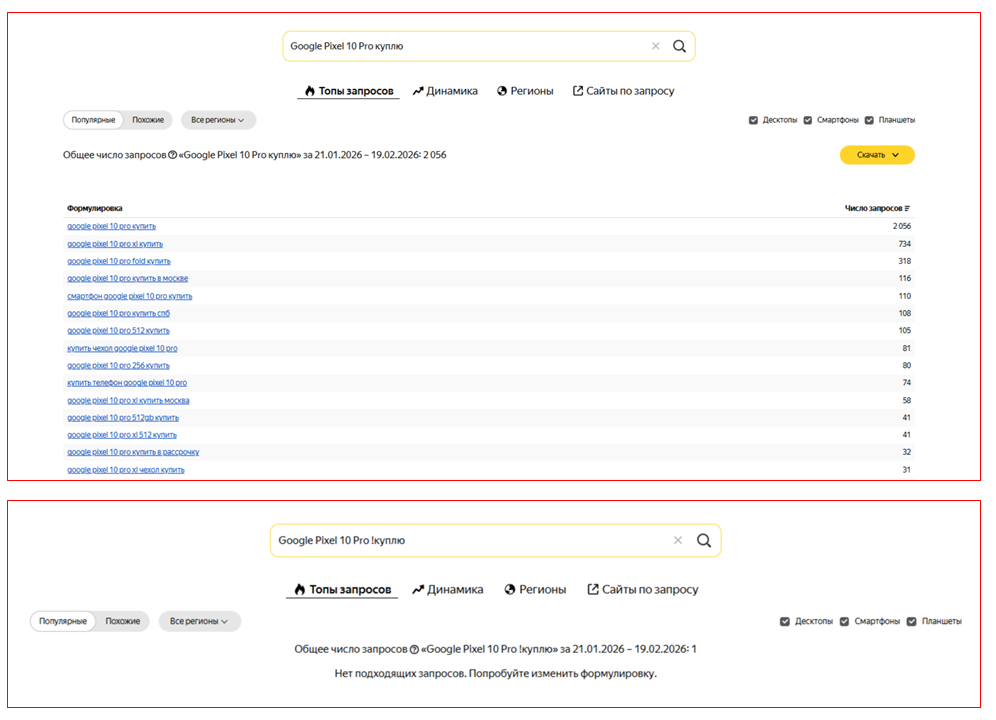
2. Восклицательный знак. Сохраняет словоформу и позволяет уточнить частотность запросов, включающих конкретное слово в конкретной форме.
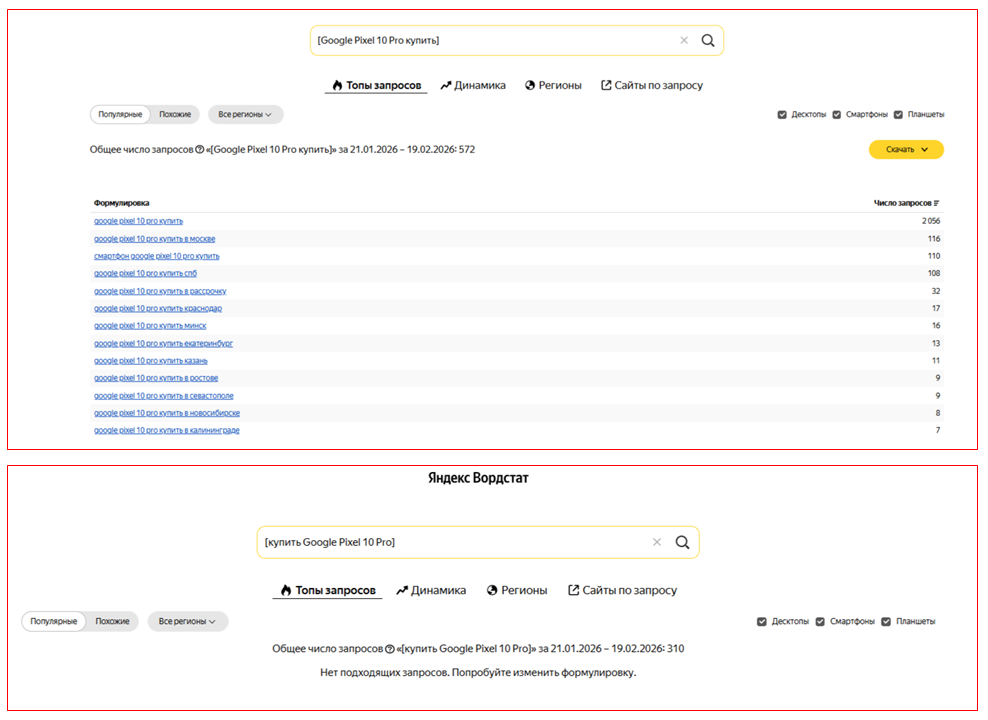
3. Квадратные скобки. Сохраняют последовательность слов и позволяют посмотреть, как расходится частотность между разными формулировками.
4. Минус. Позволяет еще на этапе сбора семантики очистить ядро от ненужных вариантов фраз.
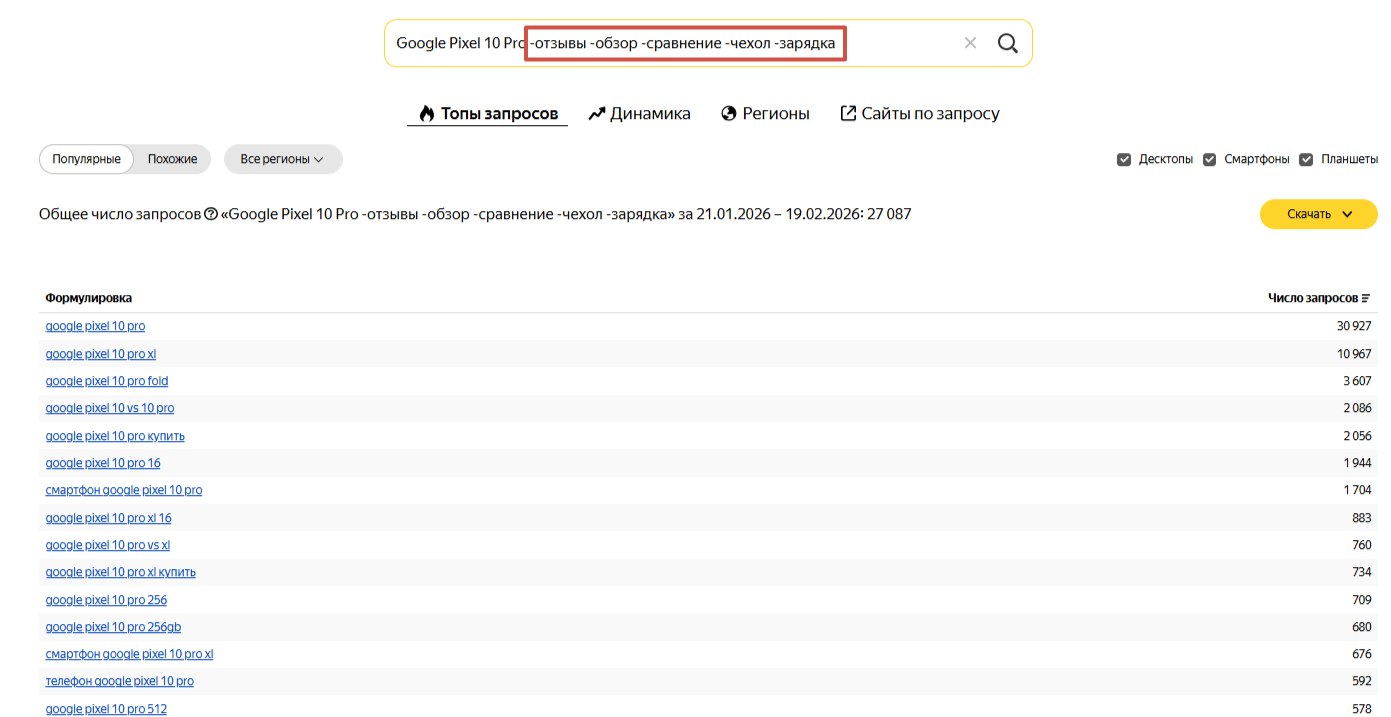
5. Комбинирование операторов. Позволяет получить максимально точную фразу и проверить частоту ее использования.
Оператор <+> перестал иметь значение для фиксации стоп-слов. Вордстат и так показывает запросы с предлогами, если они есть в фразе.
Выбор регионов
Без учета региональности данные по частотности запросов могут быть искажены за счет крупных регионов или мегаполисов. Поэтому имеет смысл проверять данные только по целевому региону либо, если планируется широкое таргетирование, по каждой области/городу отдельно. Для региональной статистики выбирайте конкретные области или города на вкладке «Регионы». В первую очередь на этой вкладке интересны данные по числу запросов. Ожидаемо, что это показатель будет максимальным в городах-миллионниках.
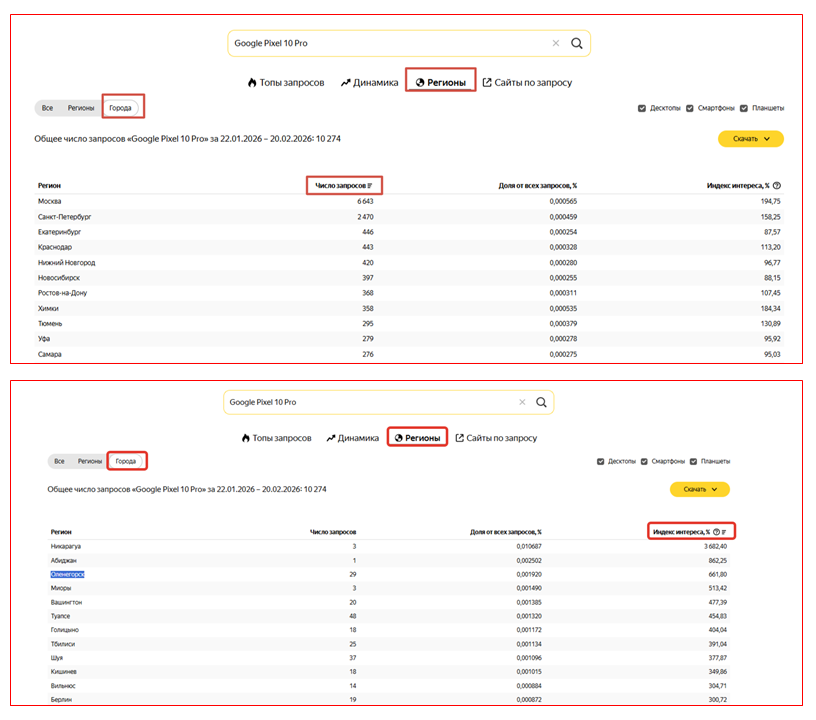
Во вторую очередь стоит обращать внимание на статистику по индексу интереса (более 100% означает повышенный интерес к продукту). В нашем примере из российских городов наибольший индекс у Оленегорска — небольшого населенного пункта в Мурманской области. Но при этом там всего 29 запросов, и при такой незначительной статистике не стоит придавать индексу большое значение. Он будет информативным только в связке с более обширным спросом.
Этот метод помогает выявить локальные ниши и сезонные всплески, что полезно для продвижения в регионах с устойчивым спросом или с резкими пиками в определенные периоды.
Сбор семантического ядра и проверку частотности запросов в конкретном регионе также можно проводить на вкладке «Топы запросов» с выбором нужной области.
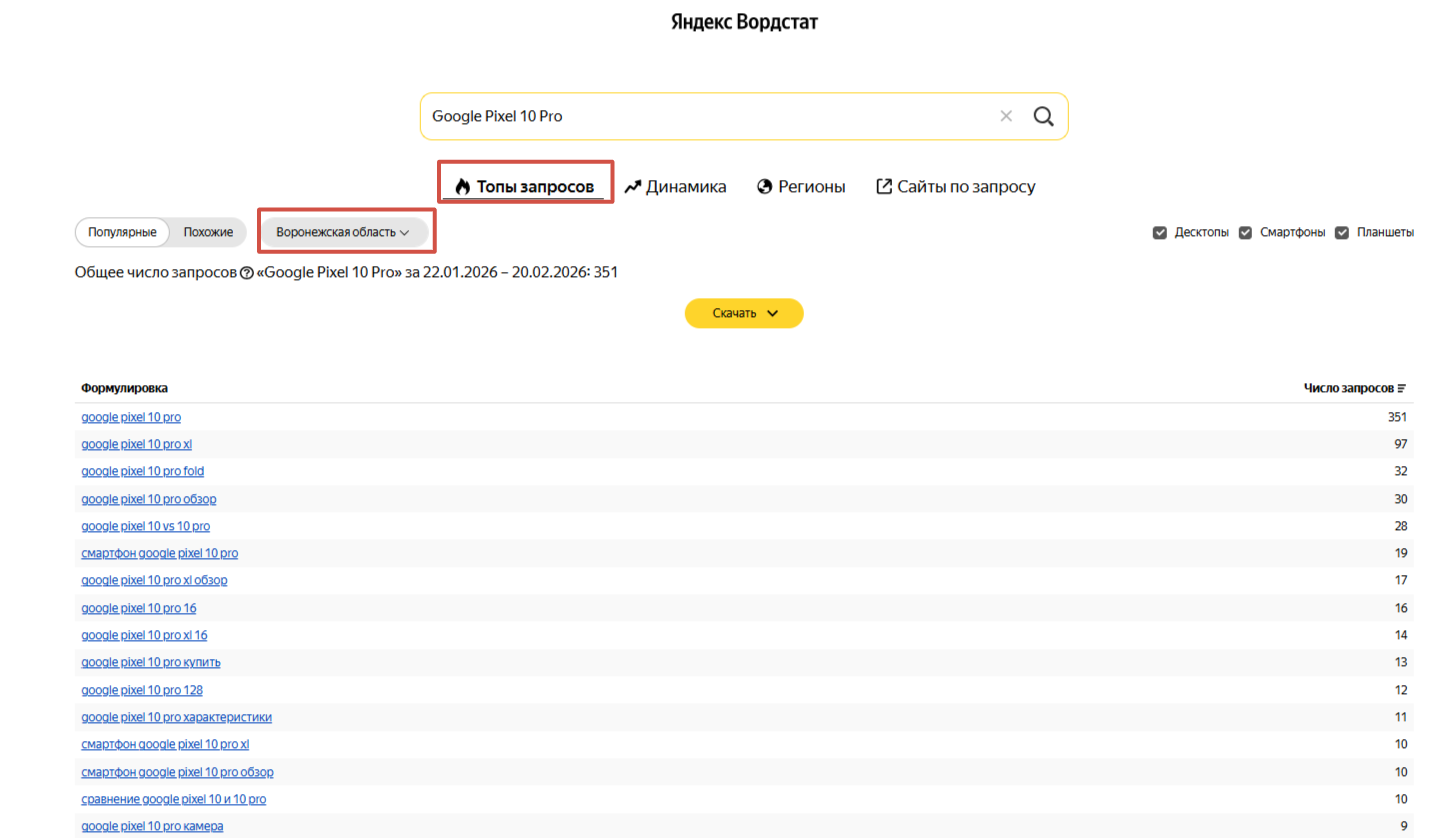
Это поможет разделить спрос по местным особенностям и локальным трендам. В дальнейшем на основе этих данных можно будет адаптировать ключевые слова и минус-фразы под локальные варианты и конкурентную среду региона.
Как использовать данные по сезонности
Изменения спроса на продукт можно отследить на вкладке «Динамика». Желательно брать максимально доступный период, но если продукт новый, анализируем данные за время с момента его выхода. Вордстат показывает динамику изменения количества запросов по дням/неделям/месяцам. Исходя из этих данных можно уточнить сезонность спроса на продукт. Логичное повышение наблюдается перед праздниками, когда люди выбирают подарки, но можно выявить и другие периоды всплесков и спадов интереса. Например, смартфон Google Pixel 10 Pro был официально представлен в августе 2025 года, и в этом месяце впервые видим реальный всплеск интереса к нему. С сентября спрос в среднем вышел на плато.
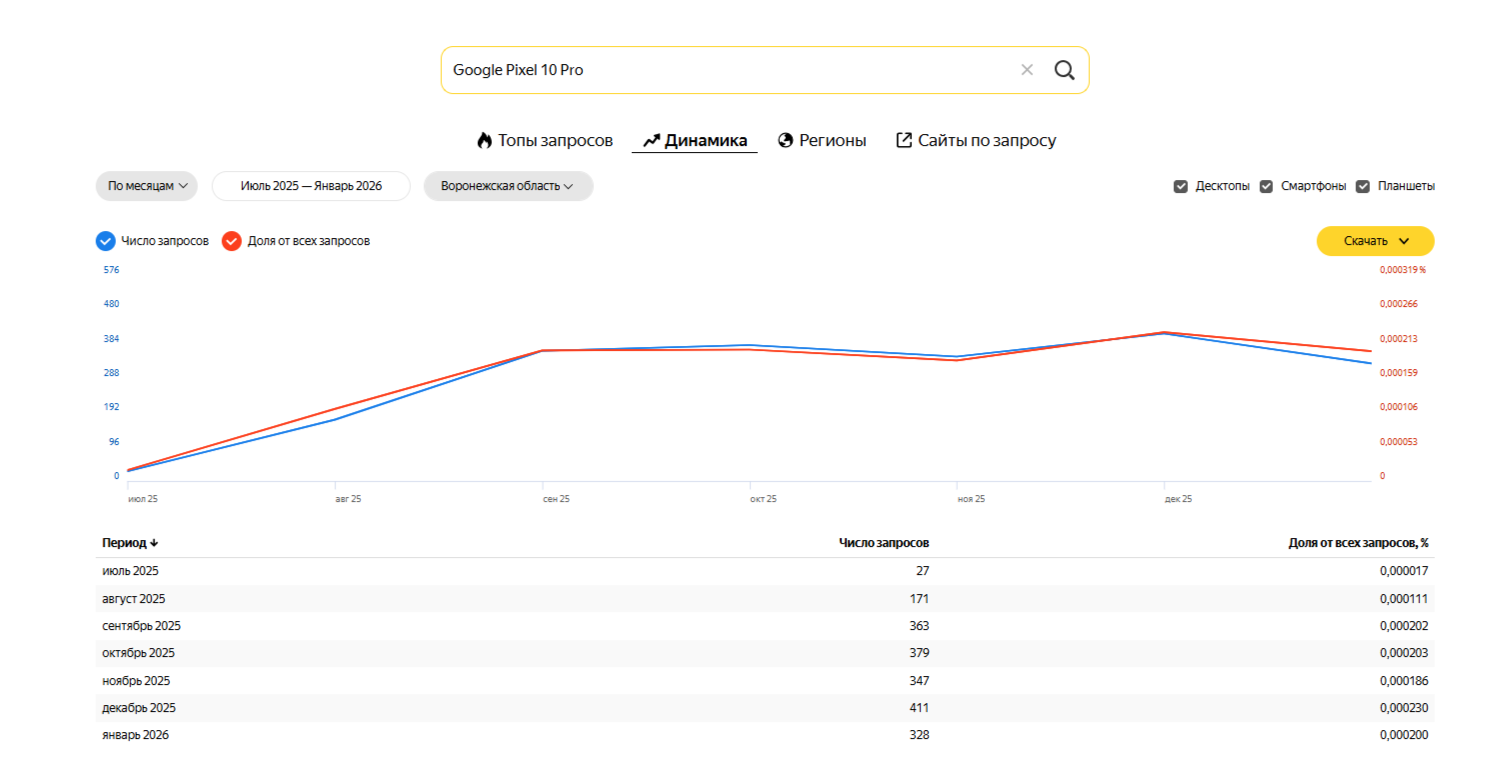
Для сравнения возьмем предыдущую модель Google Pixel 9 Pro. Она также вызвала повышенный интерес в августе 2025 года, из чего делаем вывод, что выход нового флагмана спровоцировал спрос и на прежнюю модель.
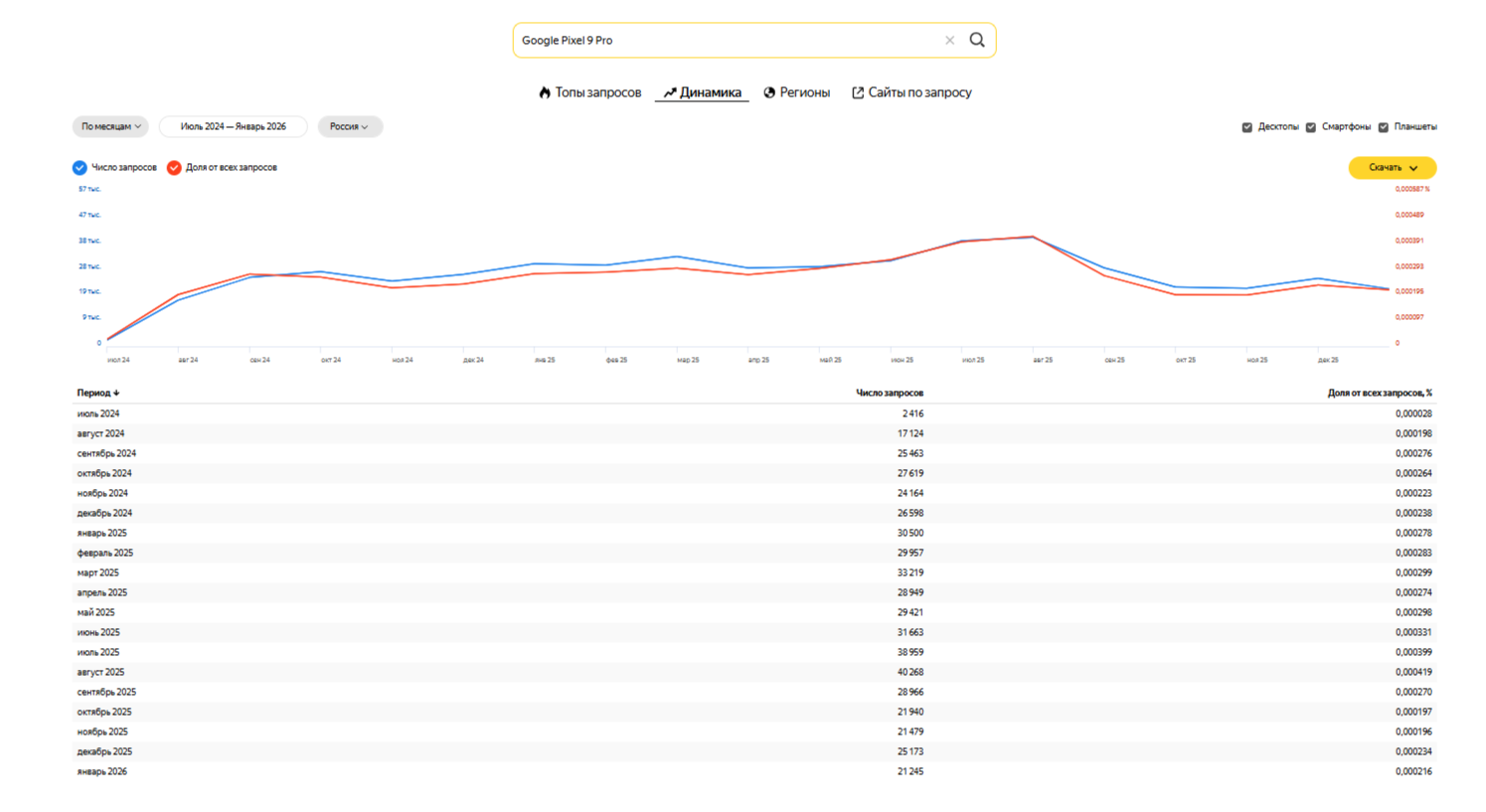
Это не совсем сезонность, а скорее, инфоповод. Но такая информация также крайне полезна для прогнозирования, а работа с сезонностью запросов строится по аналогичной схеме. В нашем примере: на 2027 год запланирован выход следующей версии этого смартфона, и на основе прошлой динамики всплесков и спадов можно будет спрогнозировать спрос на новую модель.
Расчет прогнозного трафика по частотностям
При расчете прогнозного трафика нужно помнить, что он именно прогнозный. То есть может не совпасть с реальным — и это нормально. Процесс прогнозирования состоит из следующих шагов.
Шаг 1. Частотность мы уже проверили с помощью Вордстат. Теперь определяемся, какие запросы будем применять в прогнозе: высоко-, средне- или низкочастотные. Лучше использовать все, чтобы получить максимально полную картину.
Шаг 2. Определяем CTR фраз. Если у вас есть запущенная рекламная кампания в Яндекс Директе, эти данные можно посмотреть в Мастере отчетов. Если отталкиваемся от SEO-трафика, то берем данные из отчета Яндекс Вебмастера «Статистика поисковых запросов». Если сайт совсем новый и опереться на собственные данные не получается, то можно ориентироваться на статистику по нишам и регионам в инструменте «Пульс» от click.ru — здесь представлены средние данные по результатам продвижения на разных рекламных платформах.
Шаг 3. Применяем простую формулу:
Прогноз трафика = частотность * CTR / 100%
Пример: частотность запроса
Парсеры Wordstat: когда и как использовать
Парсеры ускоряют сбор данных для уточнения частотности запросов — и делают это автоматически за несколько минут. Приведем примеры парсеров. Их можно подключить в маркетплейсе click.ru и оплачивать бонусами партнерской программы.
- Keys.so — массовая онлайн-проверка частоты запросов;
- ARSENKIN TOOLS — парсит ключи по частотности и сезонности;
- Word Keeper — облачная платформа для работы с семантикой.
Также есть парсер Wordstat от click.ru, который отличается высокой скоростью обработки и предлагает возможности разбивки по регионам и учета типа соответствия фраз (бесплатный парсинг 50 запросов для тестирования инструмента).
Использование автопарсера для работы с семантикой экономит рекламодателю время для прочих задач по планированию и настройке продвижения.







