Машинное обучение
Машинное обучение (ML, machine learning) — это область искусственного интеллекта, которая позволяет компьютерам обучаться на данных и делать прогнозы или принимать решения без четких инструкций. В ней используются алгоритмы для поиска закономерностей в данных. Чем больше информации, тем лучше алгоритм обучается.
Для чего нужно машинное обучение
Типы входных данных при обучении
Практические сферы применения машинного обучения
Виды машинного обучения
Рассмотрим основные типы машинного обучения.
1. Обучение с учителем (Supervised Learning):
- данные содержат входные параметры (X) и правильные ответы (Y);
- алгоритм обучается на размеченных данных и предсказывает результаты для новых.
Примеры:
- классификация, например спам или не спам;
- регрессия, например прогнозирование цен на недвижимость.
2. Обучение без учителя (Unsupervised Learning):
- данные не размечены, и алгоритм сам ищет закономерности;
- применяется для выявления скрытых структур в данных.
Примеры:
- кластеризация (сегментация клиентов);
- ассоциация (рекомендации товаров на маркетплейсах).
3. Обучение с подкреплением (Reinforcement Learning):
- алгоритм обучается через взаимодействие с окружением, получая награды и штрафы;
- используется в робототехнике, играх, автономных системах.
Примеры:
- обучение игровых ботов;
- управление роботами и дронами.
4. Полууправляемое обучение (Semi-Supervised Learning):
- гибридный метод (часть данных размечена, часть — нет);
- применяется, когда разметка данных дорогая или трудоемкая.
Примеры:
- распознавание лиц в соцсетях;
- обнаружение аномалий в медицинских данных.
5. Обучение на основе переноса (Transfer Learning):
- использование предобученных моделей для решения новых задач;
- применяется в глубоких нейронных сетях, например использование ResNet для анализа изображений.
Примеры:
- компьютерное зрение;
- обработка естественного языка (NLP);
- автономные системы и роботы.
6. Глубокое машинное обучение (Deep Learning, DL). Использует глубокие нейронные сети (Deep Neural Networks, DNN) для анализа и обработки сложных данных. Эти сети состоят из многих слоев нейронов, что позволяет моделям обучаться на сложных паттернах и извлекать признаки из данных.
Особенности:
- автоматическое извлечение признаков. Модель сама находит важные закономерности в данных;
- обучение на больших объемах данных. Чем их больше, тем лучше работает модель;
- использование мощных вычислительных ресурсов. Как правило, требует GPU/TPU;
- глубокие архитектуры. Содержит десятки или сотни слоев.
Основные архитектуры глубоких нейронных сетей:
- полносвязные нейронные сети (FNN, Fully Connected Networks). Используются для обработки табличных данных, классификации и регрессии. Состоят из входного слоя, скрытых слоев и выходного слоя. Применяются в прогнозировании финансовых данных, анализе клиентских данных;
- сверточные нейронные сети (CNN, Convolutional Neural Networks). Используются для обработки изображений и видео. Включают сверточные, пулинговые и полносвязные слои. Применяются для распознавания лиц, медицинской диагностики, анализа спутниковых снимков;
- рекуррентные нейронные сети (RNN, Recurrent Neural Networks). Используются для обработки последовательностей данных (текст, звук, временные ряды). Имеют обратные связи, позволяющие учитывать информацию из прошлого. Применяются в чат-ботах, машинном переводе, прогнозировании биржевых цен;
- долгая краткосрочная память (LSTM) и Gated Recurrent Unit (GRU). Улучшенные версии RNN, решающие проблему затухающих градиентов. Применяются в голосовых помощниках и для обработки текста;
- трансформеры (BERT, GPT, T5). Используются в обработке естественного языка. Включают механизм внимания (Self-Attention), позволяющий учитывать контекст. Применяются в чат-ботах, переводчиках, для автоматического написания текстов;
- генеративно-состязательные сети (GAN, Generative Adversarial Networks). Используются для генерации новых данных (изображений, текстов, музыки). Состоят из генератора (создает данные) и дискриминатора (оценивает их). Применяются для создания дипфейков, генерации картин, улучшения качества изображений.
Для чего нужно машинное обучение
Машинное обучение решает широкий спектр задач в различных сферах. Отметим основные из них.
1. Классификация. Цель — отнести объект к одной из заранее определенных категорий:
- распознавание спама в почте;
- диагностика заболеваний на основе медицинских данных;
- распознавание лиц или объектов на фото.
2. Регрессия. Цель — предсказать числовое значение на основе данных:
- прогнозирование цен на недвижимость;
- оценка спроса на товары;
- финансовые прогнозы (курс акций, стоимость нефти).
3. Кластеризация. Разделение объектов на группы без заранее известных меток:
- сегментация клиентов в маркетинге;
- группировка новостей по темам;
- анализ сетевого трафика.
5. Обнаружение аномалий. Выявление отклонений от нормы:
- обнаружение мошеннических транзакций в банке;
- выявление сбоев в оборудовании;
- поиск неестественного поведения в кибербезопасности.
6. Генерация данных (Generative AI). Создание новых данных:
- генерация изображений;
- автоматическое написание текстов;
- создание музыки и видео.
Типы входных данных при обучении
При обучении моделей используются различные типы входных данных. Они определяют выбор алгоритмов и методов обработки.
1. Структурированные (табличные) данные. Представлены в виде таблиц с четкими атрибутами (столбцы, строки):
- финансовые данные (цены, доходы, транзакции);
- клиентские данные (возраст, пол, предпочтения);
- датчики IoT (температура, влажность).
2. Неструктурированные данные. Не имеют четкой структуры, требуют дополнительной обработки:
- текст (отзывы, статьи, чаты);
- изображения (фото, медицинские снимки);
- аудио (записи разговоров, музыка);
- видео (записи с камер наблюдения).
3. Полуструктурированные данные. Содержат элементы структуры, но не организованы строго в таблицы:
- JSON, XML (данные API, веб-страницы);
- лог-файлы (записи событий в системах);
- социальные графы (связи между пользователями).
4. Временные ряды. Это данные, записанные во временной последовательности:
- курсы акций;
- данные с датчиков;
- сердечный ритм.
5. Пространственные данные и геоданные. Содержат географическую или пространственную информацию:
- координаты GPS;
- карты и спутниковые снимки;
- данные о трафике.
Типы функционалов качества
Функционал качества (функция потерь, loss function) в машинном обучении — это мера, показывающая, насколько хорошо модель предсказывает результаты. В зависимости от цели такие функции бывают нескольких типов.
1. Для задач регрессии (предсказание числовых значений). Функции потерь оценивают разницу между предсказанными и реальными значениями.
Основные метрики:
- Mean Squared Error (MSE). Среднеквадратичная ошибка:
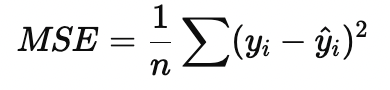
Штрафует большие ошибки сильнее, чувствительна к выбросам.
- Mean Absolute Error (MAE). Средняя абсолютная ошибка:
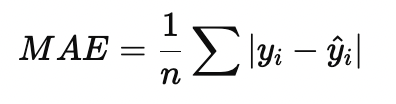
Устойчива к выбросам, но хуже дифференцируема.
- Huber Loss. Комбинация MSE и MAE, менее чувствительна к выбросам;
- R² (коэффициент детерминации). Показывает, насколько хорошо модель объясняет дисперсию данных (значение от 0 до 1).
2. Для задач классификации (разделение на классы). Оценивают разницу между предсказанной вероятностью и истинным классом.
Основные метрики:
- Log Loss (Logarithmic Loss, Cross-Entropy Loss). Функция потерь для многоклассовой классификации:
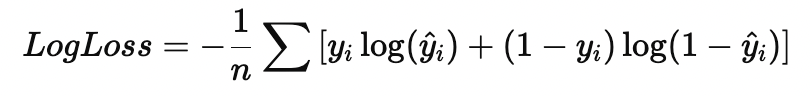
Широко используется в нейронных сетях.
- Hinge Loss. Применяется для SVM, увеличивает разницу между классами.
Метрики для оценки качества классификации:
- Accuracy. Доля правильно предсказанных классов;
- Precision, Recall, F1-score. Важны для несбалансированных классов.
3. Для кластеризации. Функции качества оценивают, насколько хорошо модель группирует данные.
Метрики:
- Silhouette Score. Оценивает плотность кластеров и их разделенность;
- Dunn Index. Показывает, насколько хорошо кластеры разделены;
- Inertia (SSE). Сумма квадратов расстояний до центра кластера.
4. Для обучения с подкреплением. Оценка качества стратегии агента.
Метрики:
- Cumulative Reward. Суммарная награда за эпизод;
- Discounted Reward. Учитывает награду в будущем, снижая ее значимость.
Практические сферы применения машинного обучения
Машинное обучение активно используется в различных отраслях, помогая автоматизировать процессы, анализировать данные и принимать решения.
1. Бизнес и маркетинг:
- персонализированные рекомендации;
- анализ поведения клиентов и сегментация;
- оптимизация рекламных кампаний (таргетинг, CPA, ROI);
- прогнозирование спроса и ценообразование.
2. Финансы и банковская сфера:
- обнаружение мошенничества (анализ транзакций);
- кредитный скоринг (оценка заемщика);
- алгоритмическая торговля на бирже;
- оптимизация инвестиционного портфеля.
3. Здравоохранение:
- диагностика заболеваний (анализ снимков, крови);
- персонализированная медицина (подбор лечения);
- анализ медицинских данных и предсказание эпидемий;
- автоматизированные чат-боты для пациентов.
4. Транспорт и логистика:
- самоуправляемые автомобили;
- оптимизация маршрутов доставки;
- анализ дорожного движения и предсказывание пробок;
- управление складскими запасами
5. Производство и промышленность:
- предсказание поломок оборудования;
- оптимизация производственных процессов;
- роботизация (автоматические сборочные линии).
6. IT и кибербезопасность:
- обнаружение кибератак и аномалий в сети;
- антиспам-фильтры и системы защиты;
- анализ вредоносного ПО.
7. Развлечения и медиа:
- рекомендации музыки, фильмов;
- генерация контента;
- автоматическая модерация контента.
8. Образование:
- персонализированное обучение (адаптивные курсы);
- автоматическая проверка работ и оценивание;
- анализ успеваемости студентов.
9. Экология и климат:
- прогнозирование климатических изменений;
- оптимизация энергопотребления;
- обнаружение загрязнения воздуха и воды.
Вопросы-ответы
Термин ввел американский исследователь Артур Самуэль, работавший в IBM. В 1959 году он разработал программу по игре в шашки, которая могла играть сама с собой и самостоятельно обучаться.
Python, R, Java, Julia, C++ и другие.
- Переобучение (overfitting). Модель слишком точно подстраивается под обучающие данные;
- Недообучение (underfitting). Модель не находит зависимости в данных.
- Смещение и дисперсия. Нарушается баланс между точностью и обобщающей способностью модели.
