20 формул Google Таблиц для контекстной рекламы


При подготовке, анализе и оптимизации контекстной рекламы возникает масса рутинных операций. Удалить пробелы и плюсики, изменить строчные буквы на заглавные, объединить массивы ключевиков, найти расхождения в данных и много другое.
На помощь приходят Google Таблицы. Мы собрали для пользователей click.ru 20 формул и показали их работу на практических примерах.
Оглавление
- 20 формул Google Таблиц для контекстной рекламы
- СЖПРОБЕЛЫ — удаляем пробелы в начале/конце ячейки
- ПОДСТАВИТЬ — заменяем буквы/символы в ячейках
- ВПР — сравниваем значения двух диапазонов данных и выводим несоответствия
- СТРОЧН — переводим буквы из верхнего регистра в нижний
- ЗАМЕНИТЬ — делаем из ключевого слова заголовок объявления
- ДЛСТР — определяем количество символов в ячейке
- ЕСЛИОШИБКА — находим ключевики в строках, чтобы разбить на группы
- SPLIT — разбиваем ключевые фразы на составные части и находим минус-слова
- СЦЕПИТЬ — объединяем текст в ячейках и генерируем UTM-метки
- REGEXEXTRACT — извлекаем нужный текст из ячеек
- GOOGLETRANSLATE — переводим ключевики и другие данные
- IMPORTRANGE — импортируем данные из других таблиц
- IMPORTXML — проверяем заполненность title и h1 на целевых страницах
- СУММЕСЛИ — находим сумму содержимого ячеек, соответствующих определенному условию
- ТРАНСП — меняем местами строки и столбцы
- XLOOKUP (ПРОСМОТРX) — сопоставляем данные из разных таблиц
- FILTER — отбираем нужные данные по заданным условиям
- QUERY — работаем с данными как с базой
- ARRAYFORMULA — применяем формулу массовых вычислений к диапазону ячеек
- LAMBDA — создаем свои формулы в Google Таблицах
- Упрощаем восприятие данных без использования формул: условное форматирование и сводные таблицы
СЖПРОБЕЛЫ — удаляем пробелы в начале/конце ячейки
Часто после сбора данных из разных источников возникает проблема: они могут быть непригодны для сводных таблиц и анализа из-за лишних пробелов в начале и конце ячейки. Сперва их нужно привести в порядок. Для этого есть функция СЖПРОБЕЛЫ.
Синтаксис:
=СЖПРОБЕЛЫ(ячейка)
или
=TRIM(ячейка)
Пример. Есть список ключевых слов для сайта по продаже полимеров и полимерного сырья, которые были собраны из разных источников. В них удалили лишние символы, но остались пробелы. Их легко убрать.
Для этого вводим в соседнем столбце формулу СЖПРОБЕЛЫ и протягиваем вниз до конца списка слов.
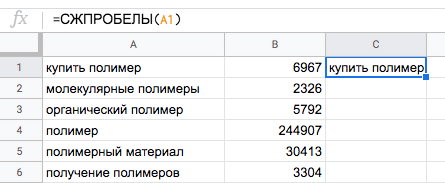
После этого выделяем столбец, копируем и вставляем в исходный столбец «Специальной вставкой» только значения.
ПОДСТАВИТЬ — заменяем буквы/символы в ячейках
После выгрузки из Wordstat слова имеют модификаторы «+», и их можно быстро заменить. Или же, наоборот, при подготовке списка ключевых слов для загрузки в Google Ads — добавить к словам модификатор широкого соответствия «+».
Синтаксис:
=ПОДСТАВИТЬ("текст"; "стар_текст"; "нов_текст"; [номер_вхождения])
или
=SUBSTITUTE("текст"; "стар_текст"; "нов_текст"; [номер_вхождения])
Пример. Выгружены ключевые слова из кампании в Яндекс Директе. Мы хотим импортировать эти слова в Google Ads. Перед тем как начать работу с ними, почистим их от знака «+».

Во втором столбце вводим формулу =ПОДСТАВИТЬ. Указываем номер ячейки, в тексте которой надо удалить плюсы. В кавычках прописываем «+», во вторых кавычках ничего не указываем (то есть менять будем плюс на пустой символ). После этого протягиваем формулу до конца списка, выделяем столбец, копируем и вставляем в исходный столбец «Специальной вставкой» только значения.
По умолчанию функция заменяет все соответствия, найденные в тексте. Если вы хотите заменить определенное соответствие, укажите его порядковый номер в последней части формулы. Если это вам не нужно, ничего там не указывайте.
Для быстрой очистки семантики от спецсимволов, пробелов и дублирующихся фраз используйте бесплатный нормализатор ключевых слов от click.ru. Там все просто: вводите список фраз — нажимаете одну кнопку и загружаете «очищенный» результат.
ВПР — сравниваем значения двух диапазонов данных и выводим несоответствия
Функция ВПР позволяет сравнить данные из одной таблицы с данными с другой и вывести в отдельный столбец все несоответствия.
Синтаксис:
=ВПР(запрос; диапазон поиска; индекс (столбец по счету из выделенного диапазона); [сортировка])
или
=VLOOKUP(запрос; диапазон поиска; индекс (столбец по счету из выделенного диапазона); [сортировка])
Пример 1. Выгружены ключевые слова из Яндекс Директа и ключевые слова из кампании в Google Ads. Нам нужно определить, каких слов, которые есть в Google Ads (столбец А), нет в Директе (столбец Е).
В скобках функции =ВПР прописываем:
номер ячейки, которую будем сравнивать;
диапазон данных, с которым будем сравнивать;
номер столбца в диапазоне данных, с которым сравниваем;
указываем логическое значение: 0 — ЛОЖЬ, 1 — ИСТИНА.
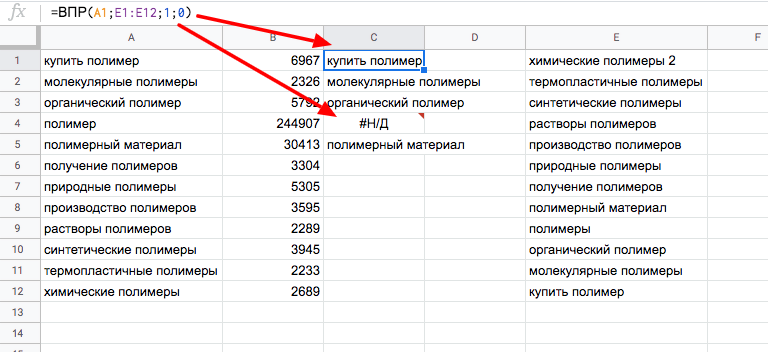
Все слова из столбца А со значением H/Д — это и есть упущенные слова, которые есть в Google Ads, но которых нет в Директе.
Пример 2. Нужно свести два разных отчета. В одном выгружена статистика по кампаниям из Яндекс Директа, во втором — данные по конверсиям из Яндекс Метрики.
Копируем данные с конверсиями на лист со статистикой Директа. Добавляем колонку G с конверсиями и прописываем в ячейке G3 функцию =ВПР. В скобках указываем первую ячейку в списке кампаний со статистикой из Директа — А3. Потом выделяем диапазон данных, из которого нужно подтянуть конверсии (это данные из Яндекс Метрики A13:B20). После точки с запятой ставим номер столбца из выделенного диапазона (в данном случае он второй). И в завершение ставим 0 — указываем, что нам нужно только точное значение.
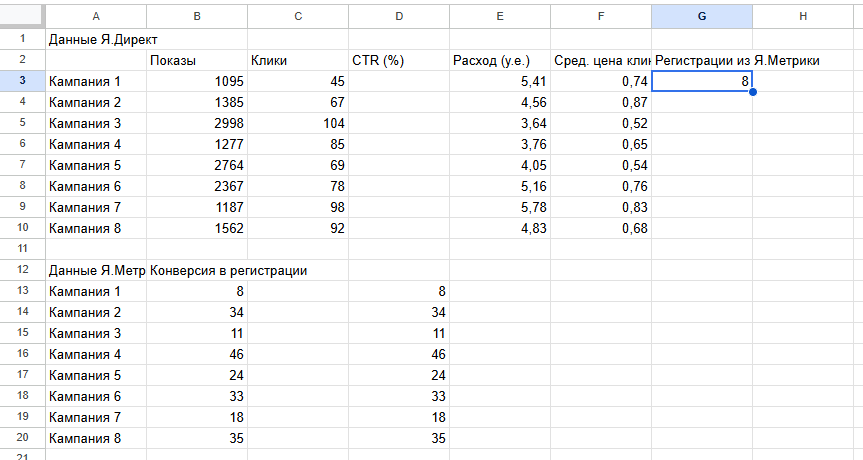
Протягиваем функцию до конца столбца с данными. Выделяем полученный диапазон, копируем и вставляем в исходный столбец «Специальной вставкой» только значения.
СТРОЧН — переводим буквы из верхнего регистра в нижний
Функция делает все буквы в заданных ячейках строчными.
Синтаксис:
=СТРОЧН(ячейка)
или
=LOWER(ячейка)
Пример. При сборе семантического ядра в список попали слова в разном регистре. Чтобы привести список слов к единому формату, воспользуемся функцией СТРОЧН.
Для этого во второй столбец вводим =СТРОЧН и указываем номер ячейки — в нашем примере это А1.
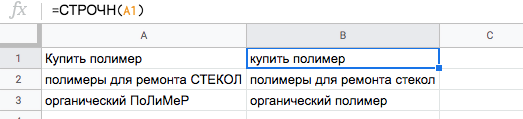
После этого протягиваем формулу до конца списка, выделяем столбец, копируем и вставляем в исходный столбец «Специальной вставкой» только значения.
ЗАМЕНИТЬ — делаем из ключевого слова заголовок объявления
Функция ЗАМЕНИТЬ поможет преобразовать первый символ в тексте в заглавную букву.
Синтаксис:
=ЗАМЕНИТЬ("стар_текст";начальная_позиция;число_знаков;"нов_текст")
или
=REPLACE("стар_текст";начальная_позиция;число_знаков;"нов_текст")
Пример. Подготовим из загруженного списка ключевых слов релевантные заголовки. Заголовки должны начинаться с заглавной буквы, поэтому применим к ключевым словам функцию ЗАМЕНИТЬ.

Расшифруем:
А1 — ячейка, текст которой должен начинаться с большой буквы;
1 — номер символа в ячейке А1, с которого начинается заменяемый отрезок текста (нас интересует первая буква, поэтому — 1);
1 — количество символов в тексте, который необходимо заменить (нас интересует только одна буква, поэтому — 1);
ЛЕВСИМВ — функция, которая выводит левый символ в ячейке;
ПРОПНАЧ — функция, которая преобразует первые буквы слов в заглавные.
После этого протягиваем всю формулу до конца списка, выделяем столбец, копируем и вставляем в этот же столбец «Специальной вставкой» только значения.
ДЛСТР — определяем количество символов в ячейке
Функция позволяет определить длину текста, содержащегося в указанной ячейке. Это полезно при составлении заголовков и текстов объявлений.
Синтаксис:
=ДЛСТР(ячейка)
или
=LEN(ячейка)
Пример. У нас есть заголовки, преобразованные из ключевых слов. Нам нужно их привести в соответствие с лимитами по количеству символов в рекламных системах.
Применим функцию =ДЛСТР. В скобках указываем ячейку, в которой нужно посчитать символы.
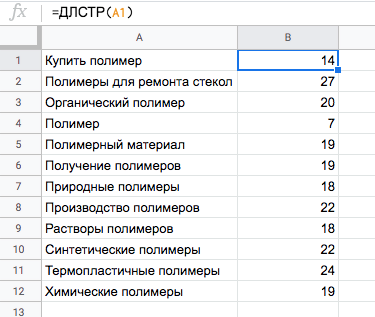
Протягиваем функцию до конца списка. Находим несоответствия. Если количество символов в заголовке превышено, то исправляем его.
ЕСЛИОШИБКА — находим ключевики в строках, чтобы разбить на группы
Функция используется для проверки формулы на наличие ошибок в первом аргументе и возвращает результат, если ошибки нет (или определенное значение, если она есть).
Синтаксис:
=ЕСЛИОШИБКА(формула;"значение в случае ошибки")
или
=IFERROR(формула;"значение в случае ошибки")
Пример. У нас есть список фраз и нам надо его разбить на группы. С помощью формулы IFERROR можно найти подходящие ключевые слова в списке фраз и в соседнем столбце указать название группы.
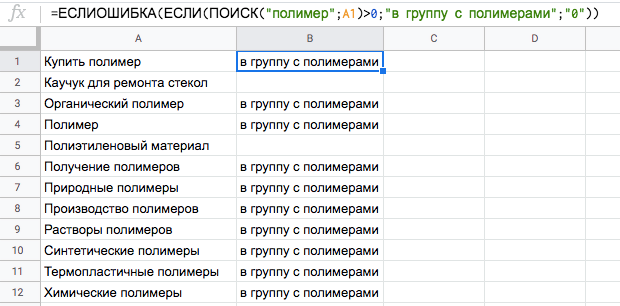
Протягиваем формулу до конца списка, копируем результат и вставляем в этот же столбец «Специальной вставкой» только значения. После этого отсортируем ключи по названию групп и дальше продолжим распределять их.
SPLIT — разбиваем ключевые фразы на составные части и находим минус-слова
Функция разносит текст в ячейке по разным столбцам.
Синтаксис:
SPLIT("текст"; "разделитель"; [тип_разделителя]; [удаление_пустых_ячеек])
Пример. Мы выгрузили маски слов из Wordstat. Теперь нужно найти минус-слова. Ускорить работу поможет функция SPLIT.
В соседний столбец прописываем функцию =SPLIT:
- указываем номер ячейки, данные которой будем разбивать (в нашем примере — A1);
- далее прописываем символ в кавычках, который разделяет слова в тексте ячейки (в нашем примере — пробел » «).
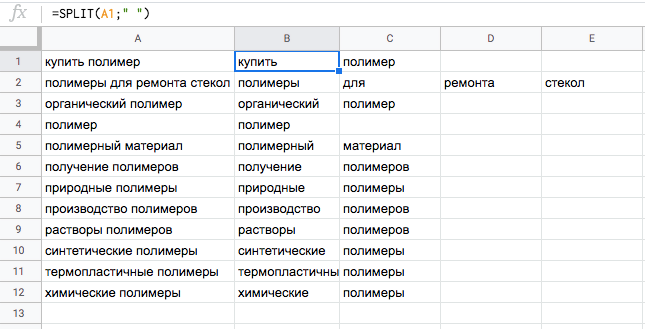
Протягиваем функцию до конца списка. Как видите, все слова разбиты по столбцам. После этого удаляем дубликаты слов, сортируем их по алфавиту и оставляем в списке только те, которые будут в кампании минус-словами.
Детально о подборе минус-слов для контекстной рекламы читайте в нашей статье.
СЦЕПИТЬ — объединяем текст в ячейках и генерируем UTM-метки
Функция позволяет объединить несколько текстовых элементов в одной строке.
Синтаксис:
=СЦЕПИТЬ("текст1";"текст2";…)
или
=CONCATENATE("текст1";"текст2";…)
Пример. Под каждое ключевое слово нам необходимо сделать ссылку с UTM-меткой.
Применим функцию СЦЕПИТЬ — объединим для каждого ключевого слова в столбце URL посадочной страницы, UTM-метки и слово в транслитерации в качестве параметра utm_term.
Для этого мы предварительно переведем в транслит исходные ключевые слова и вставим их в том же порядке в другом столбце. В соседнем столбце укажем посадочные страницы, в третьем — UTM-метки с параметрами. В столбце «Готовая ссылка» применим функцию СЦЕПИТЬ, в скобках указываем ячейки, содержимое которых будем объединять.

Протягиваем функцию до конца, копируем и вставляем в этот же столбец с помощью «Специальной вставки» только значения, чтобы данные не потерялись.
REGEXEXTRACT — извлекаем нужный текст из ячеек
Эта формула извлекает определенную часть текста, соответствующую регулярному выражению.
Синтаксис:
=REGEXEXTRACT(где искать;"регулярное выражение")
Пример. Нужно собрать домены конкурентов для настройки таргетинга по «Особым аудиториям» в Google Ads. Найти конкурентов можно, например, среди результатов кластеризации семантики, полученных с помощью кластеризатора click.ru. По каждому слову система выдаст топовую страницу в выдаче. Но целая страница нам не нужна — нам нужен только домен.
Для быстрого извлечения названия домена применим формулу REGEXEXTRACT с таким регулярным выражением:
^(?:https?:\/\/)?(?:[^@\n]+@)?(?:www\.)?([^:\/\n]+)
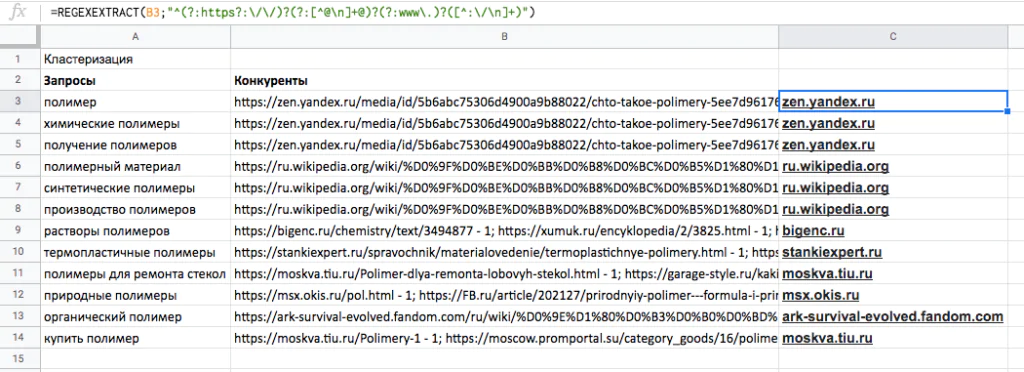
Протянем формулу до конца списка. Отсортируем по алфавиту и удалим ненужные. Список доменов можно загружать в «Особые аудитории».
GOOGLETRANSLATE — переводим ключевики и другие данные
Функция переводит текст с одного языка на другой.
Синтаксис:
GOOGLETRANSLATE(текст; "язык_оригинала"; "язык_перевода")
Пример. Хотим запустить контекстную рекламу в другой стране, и нам нужно быстро перевести ключевые слова. Используем эту функцию.
Для перевода в соседнем с ключевыми словами столбце пропишем формулу:
=GOOGLETRANSLATE(A1;"ru";"en")
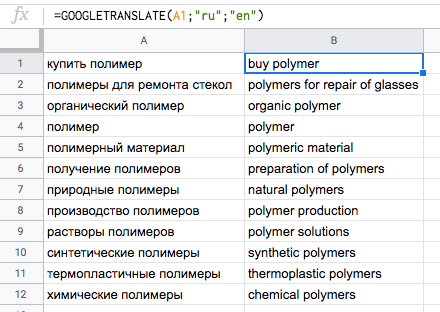
Выделим полученный список слов, скопируем и заново вставим — только значения.
С помощью этой функции можно переводить на любые языки, поддерживаемые Google.
IMPORTRANGE — импортируем данные из других таблиц
Функция импортирует диапазон ячеек из одной электронной таблицы в другую.
Синтаксис:
=IMPORTRANGE("ссылка на документ";"ссылка на диапазон данных")
Пример. Создадим отчет, в котором соберем статистику по контекстной и таргетированной рекламе. Данные нам предоставляют разные специалисты. Чтобы все это объединить на одном листе, используем функцию IMPORTRANGE.
Для этого пропишем в функции ссылку на таблицу. После точки с запятой указываем лист и диапазон данных.
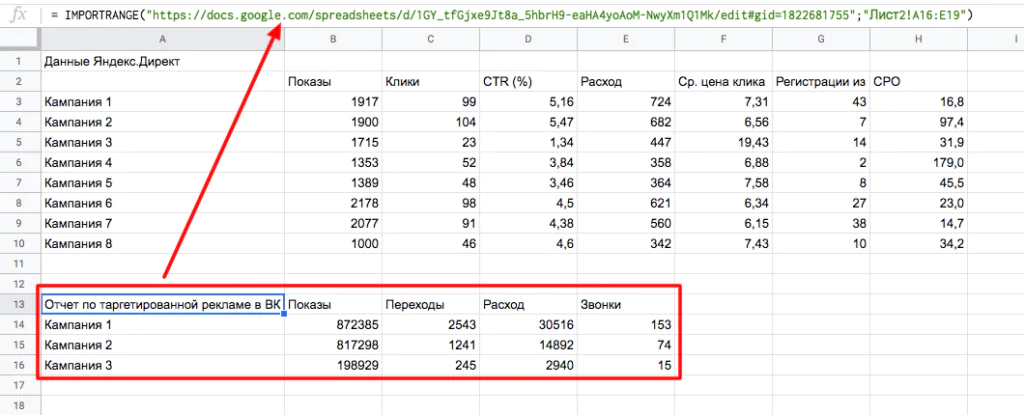
Данные загрузятся и отобразятся в этом отчете. Единственное, учтите, что у вас должен быть открыт доступ к листу, с которого загружаете данные.
Таким образом, мы вывели данные, к которым можем дать доступ клиентам или другим специалистам. При этом исходные отчеты останутся для них недоступными.
IMPORTXML — проверяем заполненность title и h1 на целевых страницах
При запуске автотаргетинга в Яндекс Директе или динамических объявлений в Google Ads важно, чтобы на посадочных страницах были прописаны релевантные теги title и h1. Для их проверки используется функция IMPORTXML.
Синтаксис:
=IMPORTXML("URL";"XPath-запрос")
Пример. Нам нужно проверить, заполнены ли теги title на страницах сайта. Вводим в первом столбце URL страниц, которые нужно проверить, а в соседнем — формулу IMPORTXML. Xpath-запрос для парсинга title выглядит так: "//title".
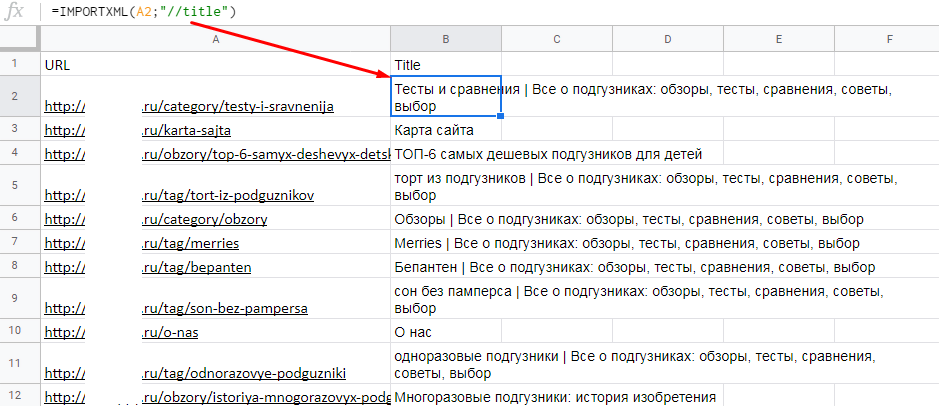
С помощью функции IMPORTXML можно собрать практически любые данные со страницы. Вот примеры других запросов XPath:
- сбор заголовков h1 (и по аналогии — h2-h6): //h1
- сбор метатегов description: //meta[@name=’description’]/@content
- спарсить мета-теги keywords: //meta[@name=’keywords’]/@content
- извлечение e-mail адреса: //a[contains(href, ‘mailTo:’) or contains(href, ‘mailto:’)]/@href
- извлечение ссылки на профили в соцсетях: //a[contains(href, ‘vk.com/’) or contains(href, ‘ok.ru’) or contains(href, ‘tenchat.ru’)]/@href
Для быстрого сбора метатегов и заголовков сразу по всему сайту используйте парсер метатегов и заголовков от click.ru. Достаточно ввести ссылку на XML-карту сайта, и инструмент спарсит данные по всем страницам. Вот гайд по инструменту.
СУММЕСЛИ — находим сумму содержимого ячеек, соответствующих определенному условию
Функция находит сумму содержимого ячеек, соответствующих определенному условию.
Синтаксис:
СУММЕСЛИ(диапазон; условие; [диапазон_суммирования])
Пример. Мы выгрузили отчет с разбивкой по типам кампаний и типам устройств. Нам нужно быстро подсчитать сумму регистраций с мобильных устройств и поисковых кампаний.
Для этого применим функцию СУММЕСЛИ — введем в скобках диапазон, в котором указан тип кампании; после точки с запятой укажем условие (в нашем примере это «Поиск»); затем — диапазон, значения в котором будем суммировать.
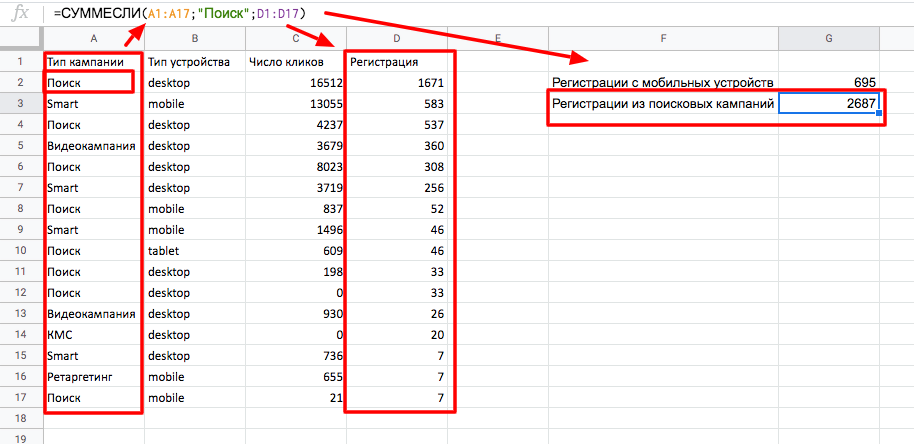
Таким образом, можно подсчитать по каждому пункту сумму регистраций или кликов.
ТРАНСП — меняем местами строки и столбцы
Функция меняет местами строки и столбцы в массиве ячеек.
Синтаксис:
=ТРАНСП(массив_или_диапазон)
или
=TRANSPOSE(массив_или_диапазон)
Пример. У нас есть данные сводной таблицы (из предыдущего примера). Но нам не удобно анализировать и сравнивать типы кампаний между собой, когда они находятся в строках. Для того чтобы отобразить те же данные в столбцах, применим функцию ТРАНСП.
В свободную ячейку прописываем =ТРАНСП и указываем диапазон — в нашем примере это A1:F5.
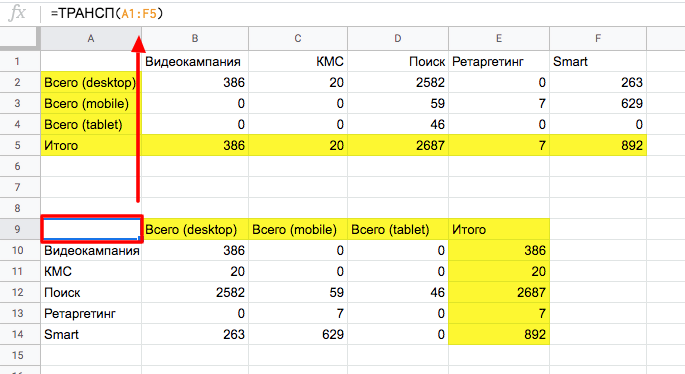
Теперь типы кампании отображаются в столбцах, и данные при этом не потерялись.
XLOOKUP (ПРОСМОТРX) — сопоставляем данные из разных таблиц
XLOOKUP — это новая продвинутая функция, которая заменяет функции VLOOKUP и HLOOKUP. С ее помощью можно выполнять поиск в заданном диапазоне как по вертикали, так и по горизонтали.
Синтаксис:
=XLOOKUP(искомое значение; диапазон/массив поиска; диапазон, из которого нужно вернуть результат)
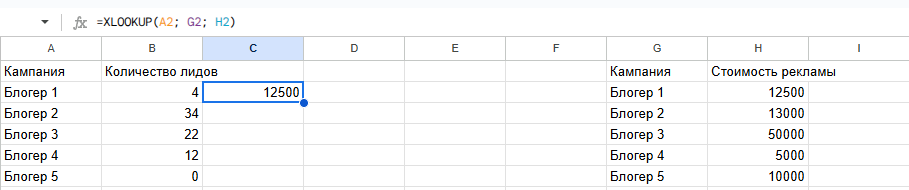
Пример. Есть две таблицы: с расходами на рекламу и с полученными лидами. Нам нужно связать их так, чтобы к каждому лиду автоматически подтягивались расходы, статус или этап воронки.
Для этого в обеих таблицах должен быть общий параметр, например ID или название кампании, UTM-метка. Важно, чтобы значения полностью совпадали, иначе функция не найдет соответствие. Таблицы нужно поместить на один лист.
В таблице с лидами в новом столбце прописывается функция XLOOKUP. В качестве первого аргумента указывается ячейка с ID кампании или лида. Вторым аргументом задается столбец с такими же ID в таблице расходов. Третьим — столбец, из которого нужно подтянуть данные, например сумму затрат.
=XLOOKUP(A2; G2; H2)
Формула ищет совпадение по ID и возвращает нужное значение из таблицы с расходами. Если соответствие найдено, расход автоматически подставляется к нужному лиду. Если соответствий нет, ячейка около лида остается пустой.
FILTER — отбираем нужные данные по заданным условиям
FILTER — это функция, показывающая только те строки или столбцы, которые соответствуют заданным условиям. Она помогает быстро отделить важные данные от общего массива и собрать рабочую выборку без ручной фильтрации.
Синтаксис: =FILTER(диапазон; условие1; [условие2; …])
Пример. Мы собрали в таблицу данные о рекламных лидах: источник, кампания, статус, количество заявок. Теперь нам нужно отобрать только те лиды, которые пришли из конкретного источника и имеют нужный статус, например «В работе».
Используем функцию FILTER. В качестве диапазона укажем всю таблицу с лидами. Условиями выступают столбцы со статусами и названиями кампаний:
=FILTER(A2:E6; B2:B6="Telegram"; C2:C6="в работе")
Функция проверяет каждую строку и выводит только те, где оба условия выполняются одновременно.

В результате формируется отдельная таблица, которая автоматически обновляется при изменении исходных данных. Это удобно для анализа эффективности кампаний, подготовки отчетов или передачи данных в работу.
QUERY — работаем с данными как с базой
Функция QUERY позволяет делать выборки, группировки и расчеты с помощью языка запросов Google. По сути, это мини-SQL внутри таблицы. Функцию удобно использовать, когда нужно получить сводные отчеты по большому массиву данных без ручной обработки.
Синтаксис:
=QUERY(данные; запрос; [заголовки])
Пример. У нас есть таблица с семантическим ядром для рекламных кампаний: ключевая фраза, кампания, количество показов и кликов. Мы хотим быстро понять, какие ключи дают лучший результат и как распределяются клики по кампаниям.
Для этого используется функция QUERY. В качестве диапазона передается вся таблица с семантикой. В текст запроса вводится:
- какие столбцы выбрать;
- как их сгруппировать;
- какие показатели посчитать.
QUERY обрабатывает данные и возвращает готовую сводную таблицу, которую можно сразу использовать в отчете для клиента. Так, в нашем примере функция группирует данные по кампаниям и показывает, по каким кликам было больше 10 кликов.

ARRAYFORMULA — применяем формулу массовых вычислений к диапазону ячеек
ARRAYFORMULA — это функция, которая позволяет применять одну формулу массива сразу к диапазону ячеек. Она автоматически рассчитывает значения для всех строк и столбцов, без копирования формулы вручную.
Синтаксис:
=ARRAYFORMULA(формула_массива)
Пример. Мы получили таблицу с данными по рекламным кампаниям: в одном столбце — количество кликов, в другом — цена клика. Нужно посчитать расходы по каждой строке и вывести их в отдельный столбец.
Обычно для этого формулу протягивают вниз. С ARRAYFORMULA достаточно прописать ее один раз в верхней ячейке столбца. Функция автоматически умножит клики на цену клика для всех строк и внесет их во все ячейки столбца. При добавлении новых данных расчеты появятся сами, без дополнительной настройки.
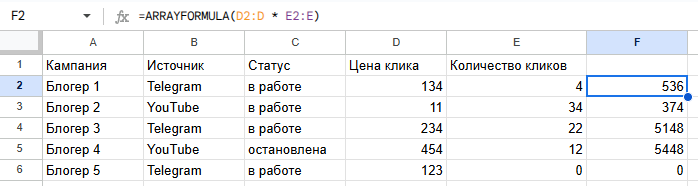
Так ARRAYFORMULA упрощает работу с отчетами и снижает риск ошибок из-за забытых или некорректно скопированных формул.
LAMBDA — создаем свои формулы в Google Таблицах
LAMBDA позволяет создавать пользовательские функции прямо в таблице. Нужно один раз описать логику расчета, задать параметры и дальше использовать его как обычную формулу, подставляя значения.
Синтаксис:
=LAMBDA(имя; формула)
Пример. Нам нужно регулярно считать рекламную комиссию или агентское вознаграждение по фиксированному проценту. Чтобы не прописывать один и тот же расчет в каждом отчете, можно вынести его в LAMBDA.
В формуле задаются параметр (например, бюджет) и логика расчета комиссии. После этого функция вызывается сразу с нужным значением. Таблица выполняет расчет по заданному правилу, без повторения формулы в каждой ячейке.
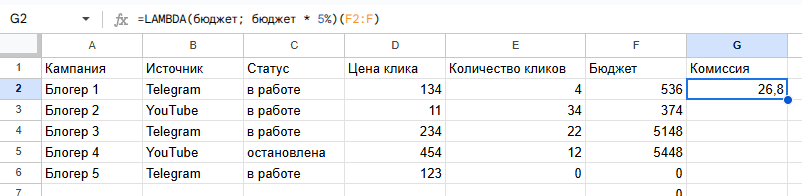
Такой подход особенно удобен в отчетах для клиентов: логика расчетов единая, формулы выглядят аккуратно, риск ошибок минимальный.
Упрощаем восприятие данных без использования формул: условное форматирование и сводные таблицы
Чтобы не просто собирать данные, но и отслеживать тренды, аномалии и ключевые показатели по всем рекламным кампаниям и каналам, не обязательно использовать формулы. Google Таблицы предлагают два простых и эффективных инструмента для визуализации данных: условное форматирование и сводные таблицы.
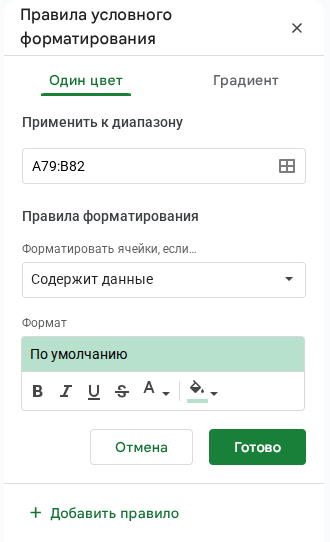
Условное форматирование
Этот инструмент позволяет автоматически менять цвет текста и фона в ячейках по заданным правилам. Например:
- красный цвет — расходы на рекламу выше среднего значения;
- зеленый — ниже среднего.
Чтобы использовать условное форматирование, нужно выделить диапазон данных, выбрать формат «Условное форматирование», задать правило и стиль выделения фона и ячеек (цвет или градиент), текста (цвет, жирный, курсив, зачеркнутый).
Сводные таблицы
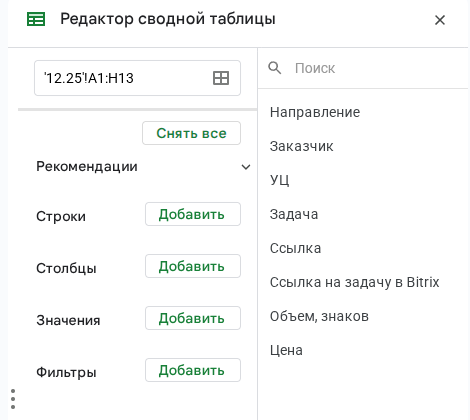
Сводная таблица позволяет сужать большие объемы данных и отслеживать их взаимоотношения. Например, с помощью этого инструмента можно удобно анализировать суммы расходов и кликов по кампаниям за месяц, средний CTR и конверсии по каналам, доходы по регионам или продуктовым категориям и т. д.
Чтобы создать сводную таблицу, нужно выделить диапазон с данными, в меню выбрать «Вставка» → «Создать сводную таблицу». Таблицу можно открыть на существующем или новом листе. Дальше потребуется указать строки и столбцы, которые должны быть в сводке, и значения для них. При необходимости можно добавить фильтры, чтобы исключить нерелевантные данные.
Чтобы зарабатывать больше на контекстной и таргетированной рекламе, подключите рекламные аккаунты ваших клиентов к click.ru и получайте вознаграждение до 19% от их расходов. Деньги можно выводить или реинвестировать обратно в кампании.
Кроме партнерской программы вы получаете другие преимущества: один договор и акт на все рекламные системы, единый баланс, приоритетная техподдержка, инструменты для автоматизации и оптимизации рекламы.







