Как быстро почистить семантику: гайд по нормализатору слов от сервиса click.ru


Сбор семантики для рекламной кампании – кропотливый и длительный процесс. Особенно если стоит задача прорекламировать широкий спект услуг или всю товарную линейку. В этом случае немало времени уходит не только на подбор релевантных ключевых фраз, но и на очистку собранных ключей от мусора – дублирующихся фраз, фраз с лишними пробелами и т. д.
Рассказываем, как автоматизировать сбор семантики и очистить ее от мусора с помощью профессиональных инструментов click.ru.
От чего нужно чистить семантику
Как собрать семантику для последующей нормализации
Как очистить ядро с помощью нормализатора слов
Чек-лист: что делать после нормализации слов
Зачем чистить семантику
Цель сбора семантики для рекламы – собрать все ключевые фразы, по которым пользователи ищут товар/услугу в интернете. Для этого используются разные источники: сервисы поисковых систем (Яндекс Wordstat, Google Trends) и профессиональные инструменты (сбор ключевых фраз по сайту, сбор ключевых фраз конкурентов, сбор ключевых слов с сервисов статистики и т. д.). Также собранное ядро расширяют с помощью фраз-ассоциаций, поисковых подсказок и т. д.
Результат такой работы – список из нескольких сотен или тысяч ключевых фраз. В этом списке могут неоднократно дублироваться ключевые слова, также в нем могут содержаться нерелевантные запросы, слова с прописными буквами и т. д. Поэтому важно чистить семантику от мусора, а потом уже запускать по ним рекламную кампанию.
От чего нужно чистить семантику
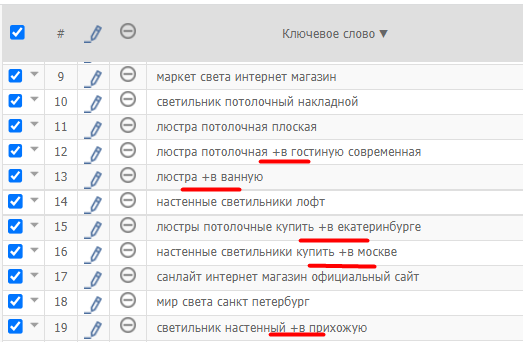
- Дублирующиеся запросы. Например, «купить потолочный светильник» и «светильник потолочный купить» одинаковые запросы.
- Специальные символы. В списке ключевых слов не должно быть точек, запятых, плюсов, скобок, кавычек, вопросительных и восклицательных знаков, а также каких-либо других символов.
- Нерелевантные запросы. Например, магазин продает светильники для дома, а в список ключевые фраз попали «уличный светильник» и «светильник для дачи». Поскольку магазин не предлагает таких товаров, то нет смысла показывать по ним объявления и тратить впустую бюджет. Чтобы не чистить от таких запросов список из тысячи ключевых фраз, нужно проработать список минус-слов. Подробнее о том, как работать с минус-словами, читайте здесь.
- Слова/буквы, написанные курсивом или заглавными буквами. В процессе сбора в список могут попасть фразы, написанные курсивом целиком или какая-то одна буква может написана курсивом. Например, не может в списке семантики находиться фраза, которая написана так: «торшер для гостиной». Такие фразы нужно удалять или редактировать.
- Пустые строки. Иногда список может содержать пустые строки. Их необходимо удалять. Все слова в конечном списке должны быть написаны строка в строку и находиться в одном столбце.
Способы очистить семантику
Есть два способа очистить семантику от мусора – вручную и с помощью автоматизированных инструментов. Вручную чистить собранную семантику долго и трудоемко: можно пропустить дубли, не заметить лишние пробелы, буквы, написанные курсивом. Поэтому мы покажем на примере интернет-магазина осветительных приборов, как собрать и почистить семантическое ядро с помощью автоматизированных инструментов click.ru.
Сервис click.ru предлагает большое количество профессиональных инструментов и позволяет автоматизировать сложные и рутинные задачи, связанные с запуском кампании. Также сервис помогает упростить работу с подготовкой отчетов, оказывает помощь агентствам, рекламодателям и фрилансерам в маркировке рекламы. Кроме того, в click.ru есть партнерская программа – к ней можно присоединиться и получать вознаграждение в зависимости от размеров рекламных оборотов.
Как собрать семантику для последующей нормализации
Если ключевые фразы еще не собраны, можно сделать это через click.ru. Регистрируемся в системе и создаем аккаунт. Далее в левом меню выбираем пункт «Все инструменты» – «Медиапланирование»:

Для настройки инструмента медиапланирования проводим такие действия: указываем URL, выбираем рекламные системы, регион для подбора ключевых фраз.
Окно настройки инструмента медиапланирования:
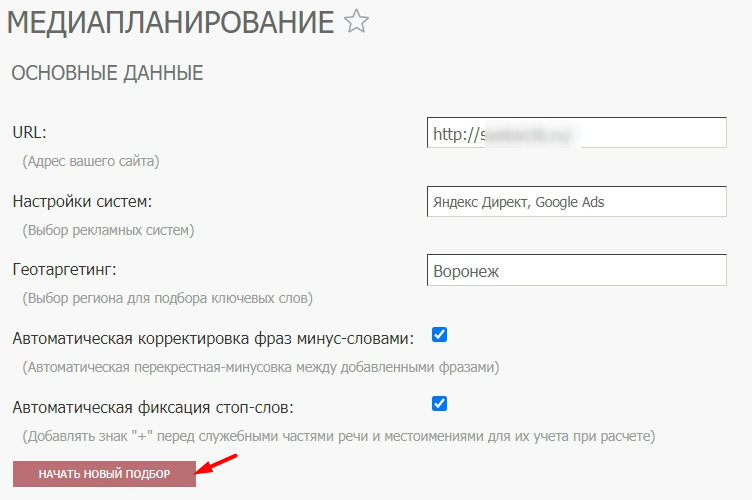
По умолчанию в настройках включены несколько опций. Рассмотрим их ниже.
1. Автоматическая корректировка фраз минус-словами. Эта функция защищает от пересечения показов по разным ключевым словам. Минус-слова добавляются к каждой ключевой фразе автоматически. Результат – упрощается работа с семантикой, поскольку не нужно добавлять минус-слова вручную.
В системе можно задать общий список минус-слов, который будет применяться ко всем ключевым фразам, собранным инструментом. Для этого надо нажать на знак «–» вверху соответствующего столбца:
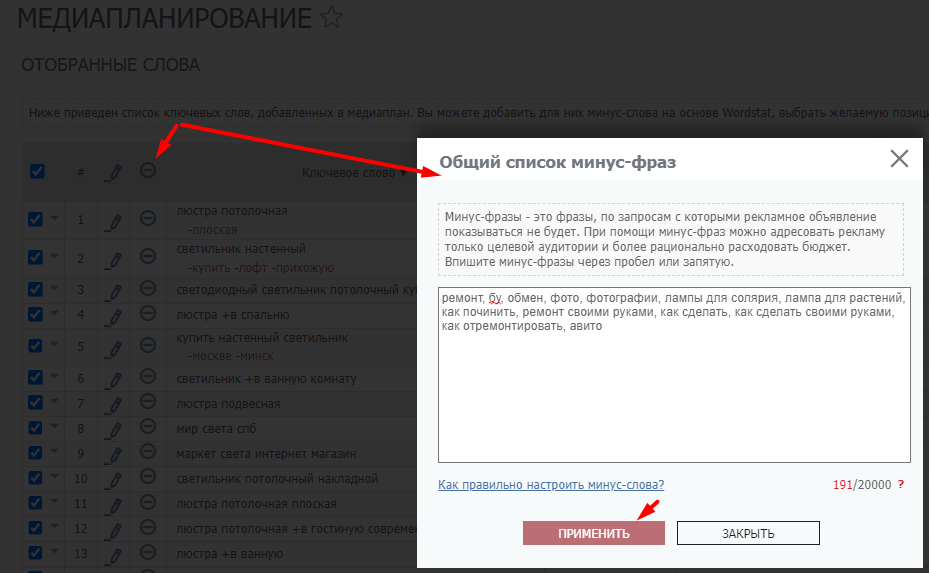
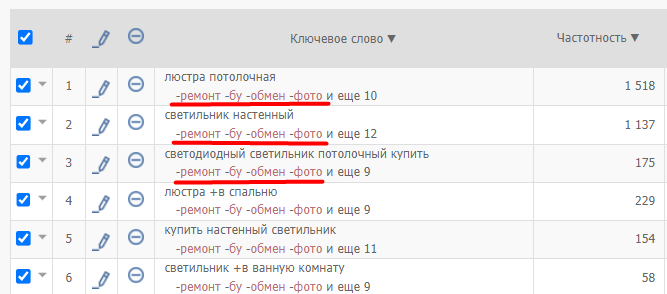
После клика на кнопку «Применить» система автоматически добавит к каждому слову общий список минус-фраз:
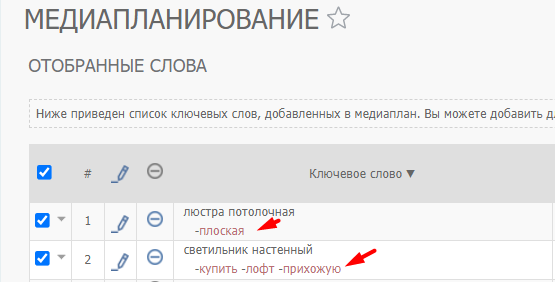
Также в инструменте предусмотрена возможность работы с минус-словами на уровне слов: можно добавить другие минус-слова и/или удалить подобранные системой слова.
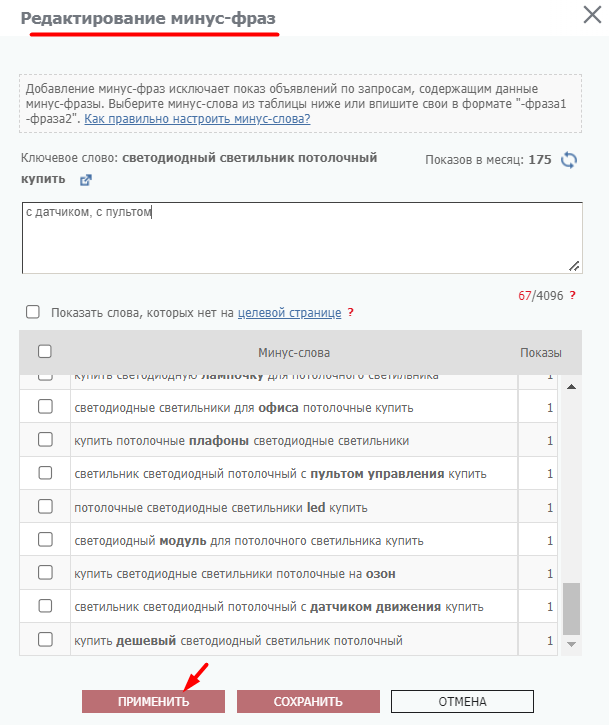
Для этого нажимаем на знак «–» напротив ключевой фразы и задаем подходящие минус-слова:

В открывшемся окне пишем список минус-слов. Ограничение – не более 4096 символов. После сохранения изменения к выбранному слову добавятся указанные минус-фразы.
Подробнее о проведении кросс-минусации читайте здесь.
2. Автоматическая фиксация стоп-слов. Инструмент автоматически добавляет знак «+» перед служебными частями и местоимениями для включения их в поисковую фразу. Например, рекламодатель хочет показывать рекламу по фразе «Как купить светильник». Если перед «как» не поставить «+», то поисковая система будет опускать вопрос «как» и показывать фразу в ответ на запрос «купить светильник».
Чтобы инструмент начал собирать семантику, кликаем по кнопке «Начать новый подбор».
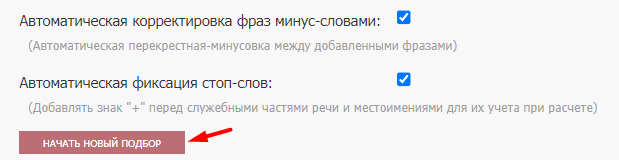
Инструмент собирает слова на основании контента сайта, URL которого указан в первоначальных настройках. В процессе сбора он отобрал 86 ключевых слов.
Указанные слова добавляем в медиаплан. Для этого ставим галочку вверху в соответствующем столбце (галочки появляются автоматически возле каждого слова в таблице) и нажимаем на «Добавить в медиаплан».
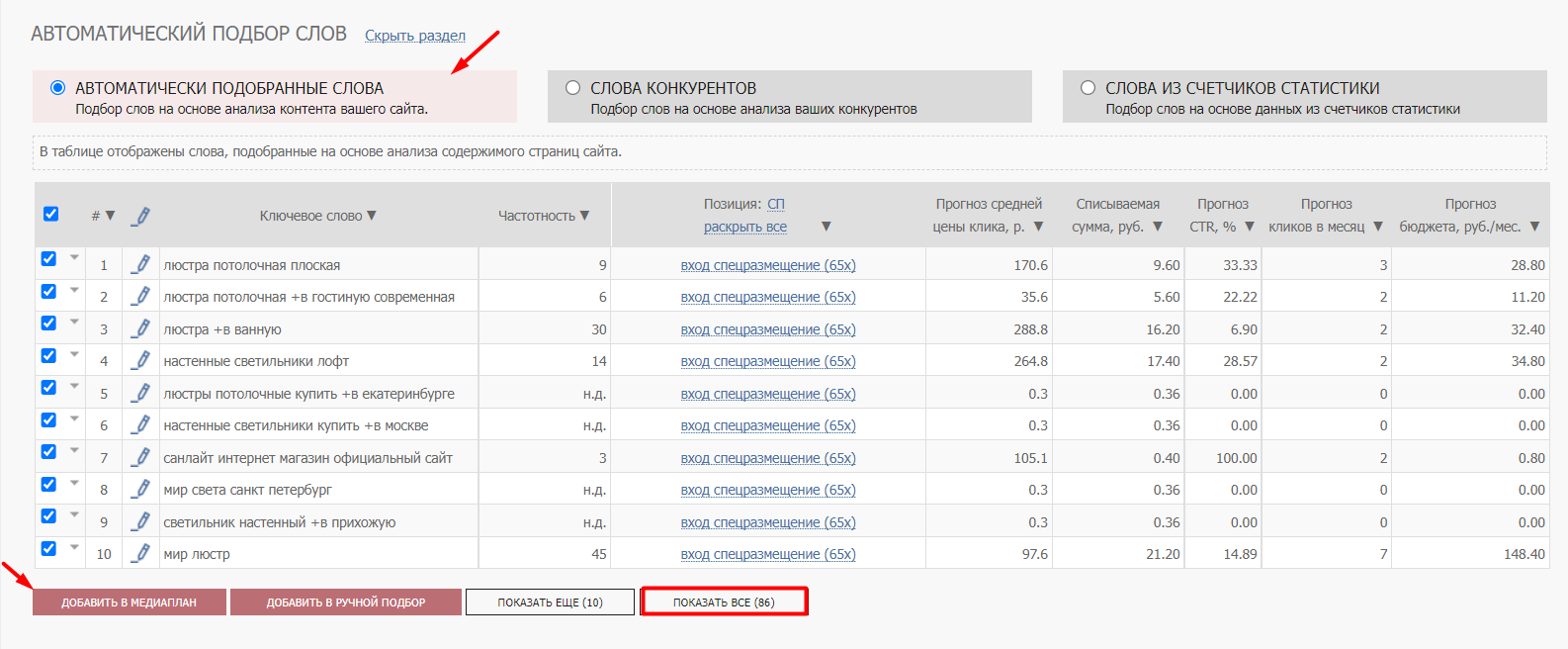
86 слов недостаточно для того, чтобы собрать полное семантическое ядро для рекламы. Для расширения собранной семантики можно воспользоваться инструментом «Слова и объявления конкурентов». По умолчанию система сама подбирает конкурентов и собирает ключевые фразы, по которым они показывают целевой аудитории свою рекламу. В настройках можно указать своих конкурентов. Ограничение – за один раз можно собрать ключевые слова по 4 конкурентам.
Кликаем на кнопку «Показать слова конкурентов»:
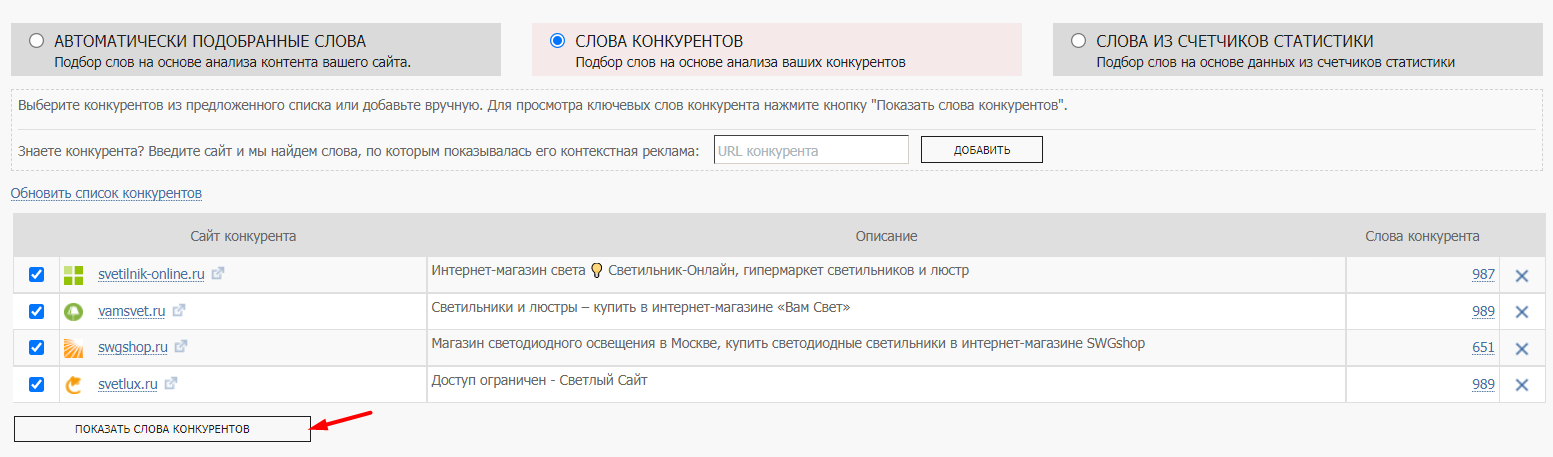
Всего инструмент собрал 2465 слов. На данном этапе можно не тратить время на просмотр собранных ключевых фраз и очистку семантики: детально проработанный список минус-фраз в медиаплане и инструмент нормализации ключевых слов позволят избежать рутины.
Собранные ключевые фразы конкурентов также добавляются в медиаплан:
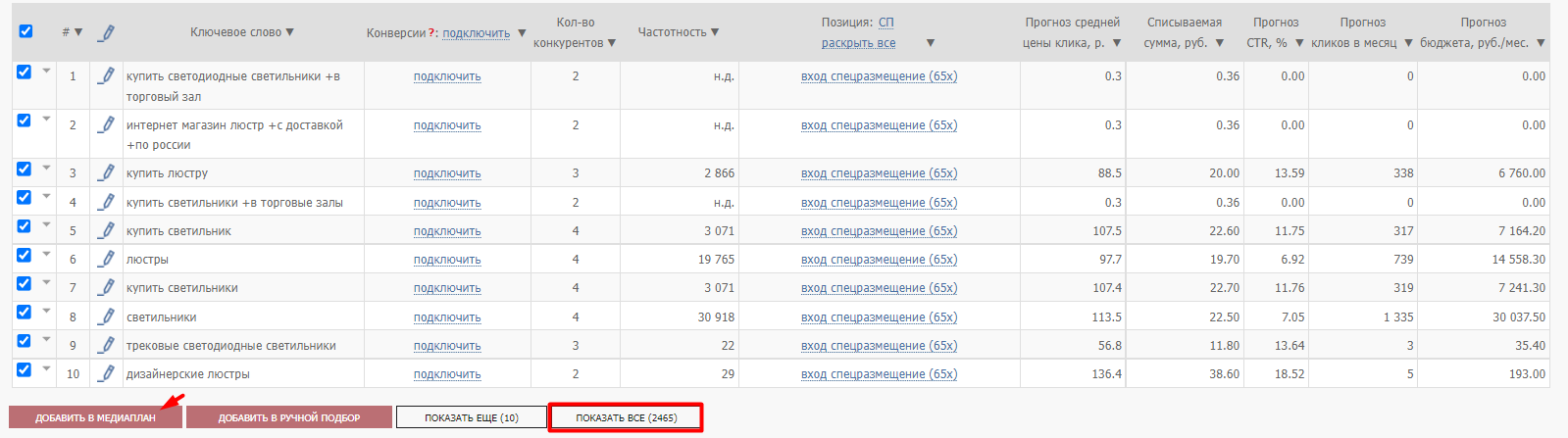
В рассмотренном примере удалось собрать достаточно широкое семантическое ядро с помощью всего двух инструментов: инструмента автоматического сбора ключевых слов и инструмента, который собирает слова конкурентов.
Также можно воспользоваться ручным подбором и с его помощью расширить семантическое ядро. В ручном подборе слов нужно ввести ключевую фразу в строку. Система расширит фразу похожими по интенту ключевыми запросами и покажет по каждой фразе статистику (частотность запроса, стоимость клика, CTR и т. д.). Останется только отметить галочками подходящие запросы и добавить в медиаплан.
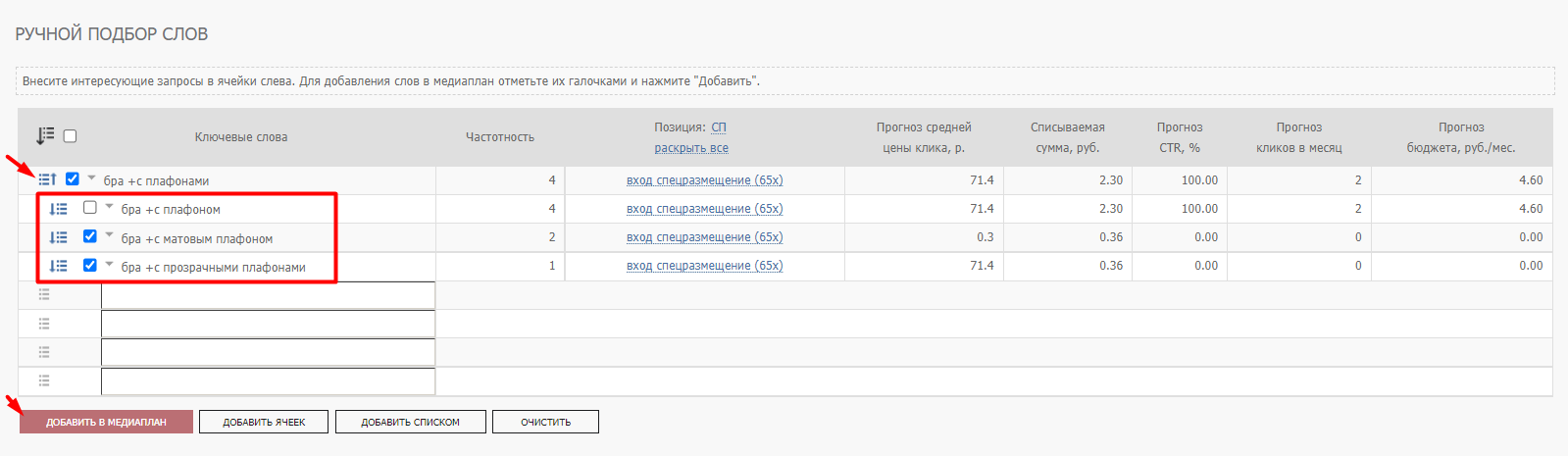
После сбора достаточного количества ключевых фраз добавляем их в медиаплан:
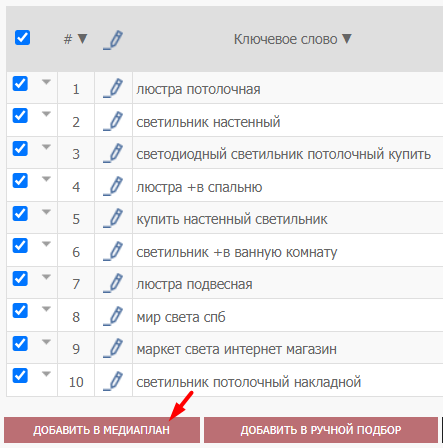
При добавлении ключевых слов система автоматически находит дубли и предлагает их удалить. То есть, уже на этом этапе работы с семантикой инструмент проводит первоначальную очистку ядра и убирает дублирующиеся фразы.
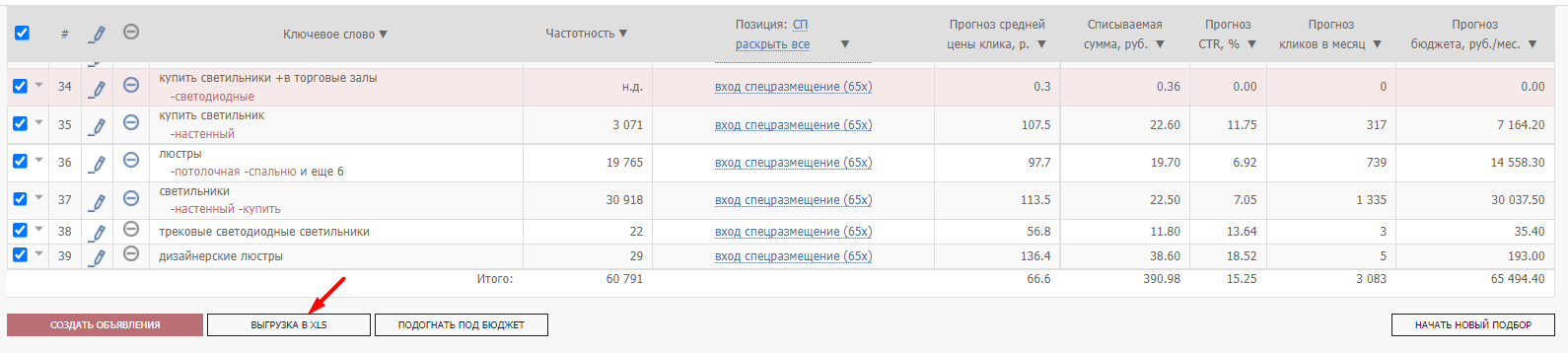
В инструменте медиапланирования можно выгрузить собранную семантику в XLS-файл. Для этого внизу медиаплана нажимаем на кнопку «Выгрузка в XLS»:
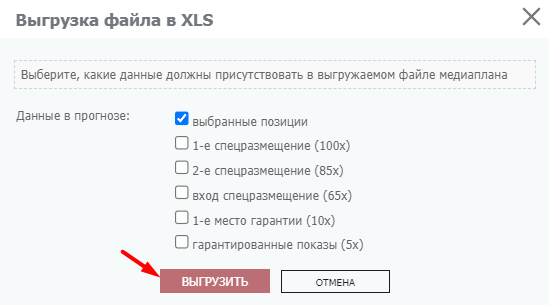
При выгрузке выбираем позиции, которые должны присутствовать в выгружаемом файле медиаплана, и нажимаем кнопку «Выгрузить».
Как очистить ядро с помощью нормализатора слов
После выгрузки семантики в XLS мы получаем ключи в таком виде:
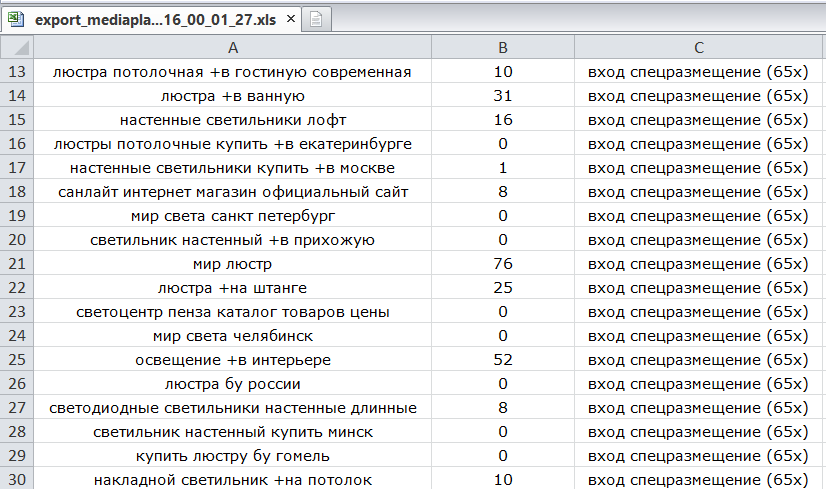
Это не очищенные от мусора ключевые фразы. Для очистки семантики в левом меню выбираем «Все инструменты» – «Нормализатор слов».
На странице инструмента нужно нажать «Добавить задачу» и внести список фраз для проверки. Это можно сделать двумя способами: вставить список фраз в соответствующее окно или загрузить в систему XLSX-файл.

Требования к загружаемому в систему XLSX-файлу: в файле может находиться только список запросов. Запросы должны располагаться в одном столбце, в одной ячейке должен находиться один запрос.
Далее смотрим настройки ниже. В пункте «Необходимые действия с ядром» ставим галочки напротив тех действий, которые надо провести для очистки семантики.
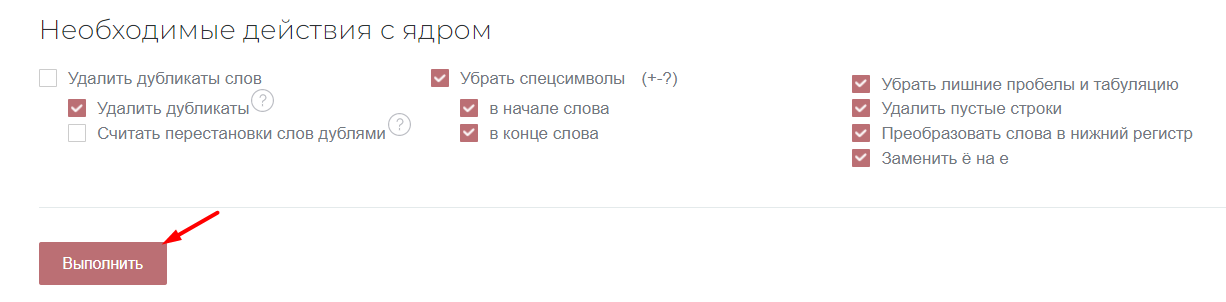
Какие действия с ядром выполняет инструмент нормализации:
- Удаляет дубликаты. Если установить галочку напротив пункта «Удалить дубликаты», то система будет убирать ключевые фразы, которые полностью дублируются. Если установить галочку напротив пункта «Считать перестановки слов дублями», то такие фразы, как «Купить светильник светодиодный» и «Светодиодный светильник купить» инструмент будет считать дублирующимися и удалять их. В результате останется только та фраза, которая находится выше по списку;
- Удаляет спецсимволы. Удаляет такие знаки, как «+», «-», «?». В настройках можно указать, где удалять спецсимволы: в начале слова или в конце. Поскольку спецсимволы могут находиться в любом месте, то рекомендуется указывать два эти пункта;
- Удаляет лишние пробелы и табуляцию. При сборе ключевых фраз в списке могут оказаться фразы с дополнительными пробелами между словами, в начале или в конце текстовой строки. Где бы ни находились лишние пробелы, инструмент обнаруживает и удаляет их;
- Удаляет пустые строки. Если в списке попадаются пустые строки, то нормализатор удаляет их;
- Преобразовывает слова в нижний регистр. Иногда в процессе сбора ключей могут быть спарсены заголовки. В этом случае в список собранных фраз могут попасть слова, напечатанные заглавными буквами. Инструмент обнаруживает такие слова и фразы и преобразовывает их в нижних регистр;
- Меняет букву «ё» на «е». Каждая площадка имеет свою редакционную политику и свое отношение к написанию в словах буквы «ё».
Можно поставить галочки напротив всех пунктов или выбрать какие-то определенные.
После клика по кнопке «Выполнить» инструмент приступит к выполнению задачи. Когда работа по нормализации ключевых фраз будет окончена, в списке задач в столбце «Статус» будет написано «Выполнен». При необходимости списку можно дать название, чтобы потом можно было с легкостью его найти среди остальных задач.

Вот так выглядит список после нормализации:
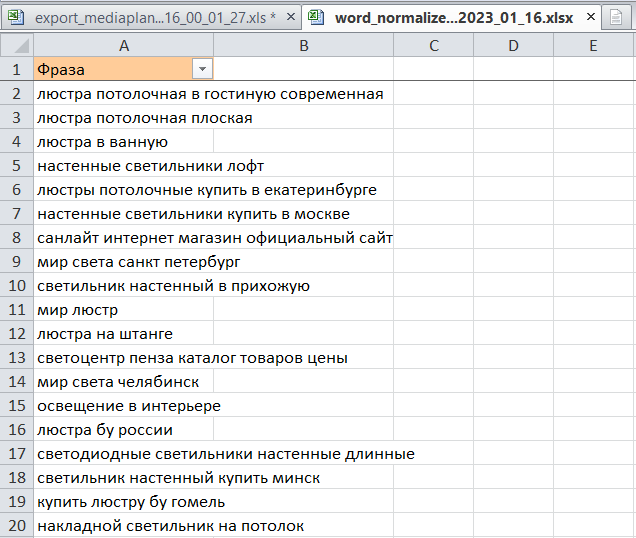
В нашем примере задача по нормализации списка слов была выполнена менее чем за 20 секунд.
Кстати, инструмент может не только навести порядок в семантическом ядре, но и быстро избавить от ненужных символов любой другой список.
Чек-лист: что делать после нормализации слов
Работа над очисткой семантики от дублей и мусора закончена. Остается сделать еще пару шагов перед запуском рекламной кампании:
1. Очистите семантику от ключевых фраз с нулевой частотностью. В собранном семантическом ядре нередко попадаются ключевые фразы с частотностью, которая стремится к нулю. Показ объявлений по таким запросам не приведет трафик на сайт, и кампания будет работать неэффективно.
Для исключения таких непопулярных запросов из семантического ядра в системе click.ru предусмотрен автоматизированный инструмент – парсер Wordstat. С его помощью можно быстро исключить из списка фразы с частотностью ниже 1–20.
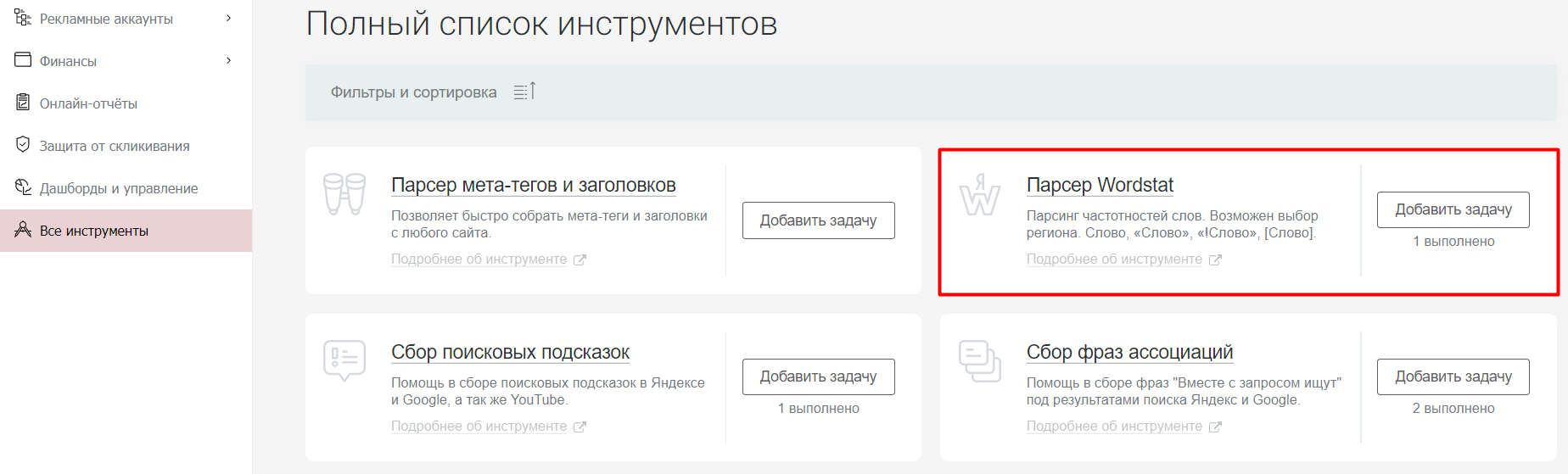
Подробнее о том, как использовать парсер Wordstat и собирать ключевые слова нужной частотности, читайте в статье «Яндекс Wordstat: как применять в контекстной рекламе».
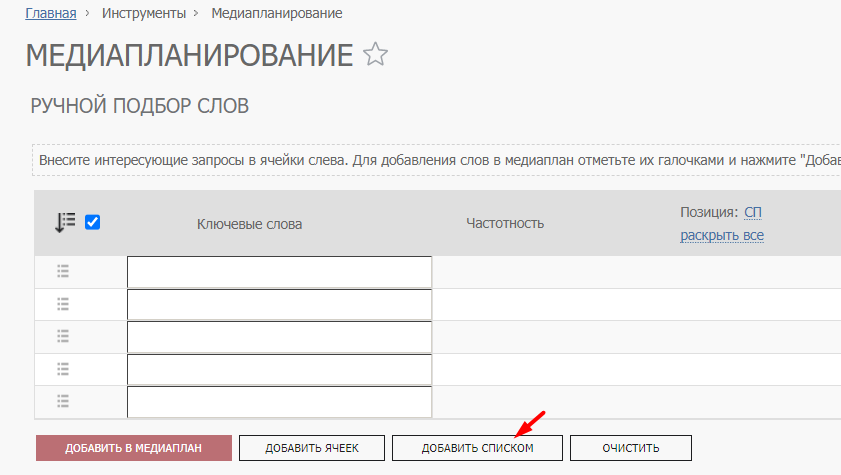
2. Загрузите проработанный список ключевых фраз в систему click.ru. Для этого повторно зайдите в инструмент медиапланирования, создайте новый проект и внесите собранную и очищенную семантику списком – кнопка «Добавить списком».
3. Создайте объявления и запустите кампанию. По добавленным в медиаплан словам можно начинать работать. Для этого нажмите кнопку, указанную на скриншоте:
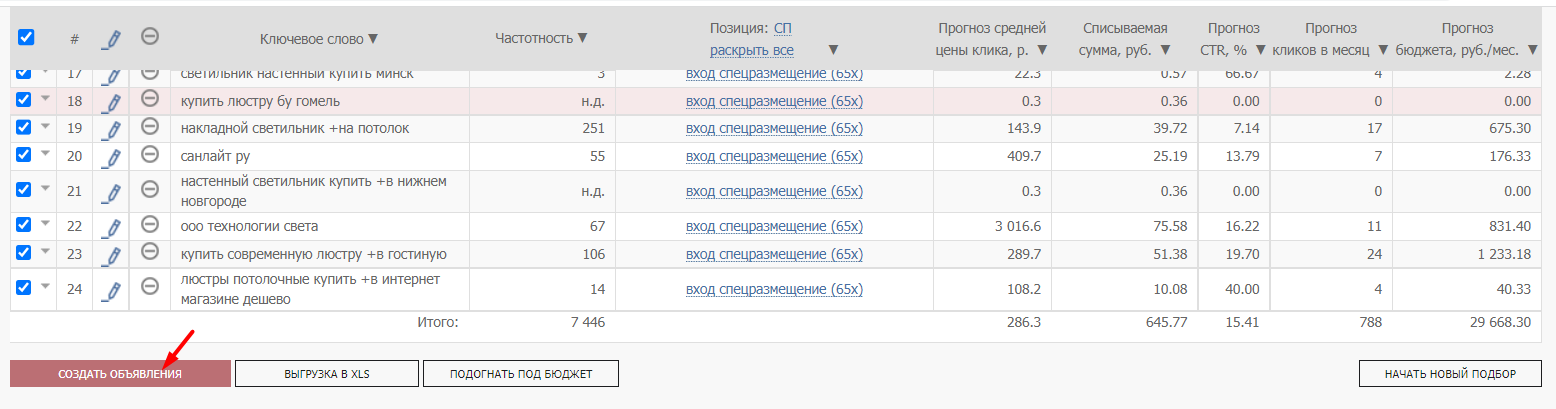
Система автоматически сгенерирует объявления с заголовками, текстом и картинками. Вам останется только отредактировать их и запустить кампанию.








